
赚钱这事儿,如何放心交给机器打理?
2019-01-17

意见
反馈

回到
顶部

Byrant,Ton & Owen 2018-04-08
我们每天都会接触大量广告,但我们很可能低估了广告的影响力。研究证明,仅仅是让人们对产品、事件以及品牌有所察觉,就可以提高人民最终购买产品、参加活动或支持这个品牌的几率。若一个广告能够足够吸引人的注意力以至于让他立刻做出积极的反应,那么这几率会进一步大幅提高。
移动广告是出现在移动设备上的广告。它通过实时竞价(RTB)系统完成。一个移动设备用户以及它移动设备上的可以显示广告的空间形成一个“竞价标的”。广告公司们在几毫秒之内就完成对这一广告位的竞价,最终胜出的可以将自己客户的广告显示出来。这个广告被记做一次Impression(展示量,也有翻译为广告印象),而用户也可以继续点击广告链接了解更多信息,这个点击即Click。每个Impression获得的点击通过率,即CTR(click through rate ),可以衡量一个广告是否成功。下图描述了这一过程。
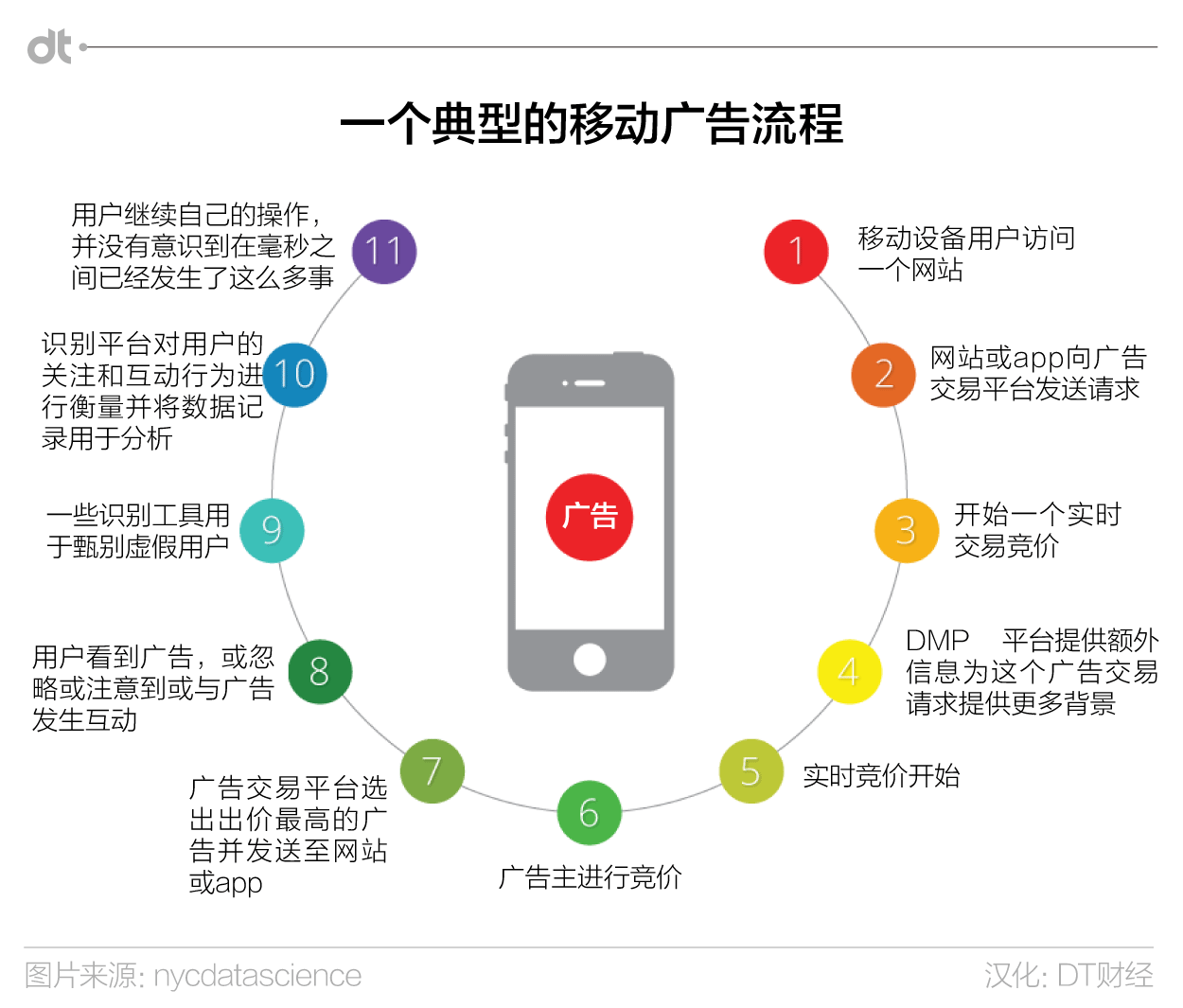
我们的项目中,我们扮演了为广告公司“AA”( Ads Anonymous ,下称AA,一家匿名广告公司)提供咨询服务的角色。它的主要目标是提高RTB过程中最终获取的广告印象数,并最终提高点击通过率。我们的角色就是建立一个机器学习框架,可以用于帮助“AA”设计出能提高其精确点击可能性的广告策略。
所以我们的项目基于两个假设。
第一个假设是,一个特定广告的点击概率取决于:
这个广告的具体细节(相关度,吸引力,品牌识别度等)
受众、用户的具体情况(年龄,性别,地域等)
要如何理解这个假设呢?具体请设想以下假设情景:
所有类型人群对于某一个一般广告的点击概率是0.15,但是对于德克萨斯州的用户这一概率是0.08.也就是,得州人与总体人群相比,更不可能点击这个广告。
德州人点击这个一般性广告的概率是0.08,但点击一个受欢迎的卡车广告则是0.2。这就是说,与这个一般性广告相比,得州人更可能点击这个卡车广告
所有类型的人群对于某一个一般广告的点击概率是0.15,但点击一个受欢迎的卡车广告的概率是0.2。也就是所有人都更可能点击卡车广告。
这三种情况如下所示:

(图片说明:黄色=0.08,橙色=0.15,红色=0.2)
由此引出的第二个假设是:只有当定制化的点击率预测比普通预测更加精准时,“AA”的客户会更喜欢为他们的广告项目(一组广告)量身定制的点击率预测模型(下称 campaign-specific模型)。因此,我们需要证明,我们的定制化模型更加有效。
总的来说,我们的方法就是使用具体项目的数据对两个 campaign-specific模型和一个普通模型进行比较。下图是工作流程。接下来我们会具体讨论每个模块。
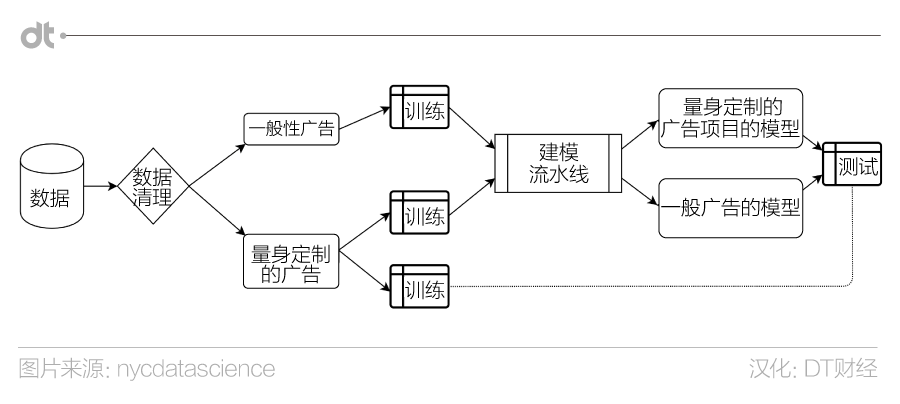
“AA”公司为我们提供了三组数据
360亿个bid request,大约30 TB 的数据量
3亿次Impression,这些是AA赢下的bid request
50万次点击, Impression的一个子集
不幸的是,AA无法获得那些他们没能赢下的bid request的相应数据。因此我们决定去掉bid request的数据,只用后两组数据。由于点击数据是Impression数据的一个子集,我们可以将两者合并成一组数据。最终,鉴于AA的建议,我们仅留下美国地区的Impression和CTR不是0的广告活动。因此最终用于训练模型的数据是CTR为0.63%的7300万次Impression数据。
由于上面提到的缺陷,我们的模型内在地偏向AA赢得的那些bid requests。因此我们做了一个假设:我们用来训练模型的Impression可以代表所有可能的Impression。
首先是数据清洗。
与每个Impression有关的数据维度包括:与用户有关的变量,用户设备,广告,广告出现的app,Impression来自的那个bid request。
我们抛弃了无用的数据,把容易给机器训练模型造成混淆的数字转换成字符,并进一步挖掘了一些新的变量。比如,我们假设人们在每周的不同日期有不同点击偏好,因此我们将日期对应的星期提取出,形成新的变量。再比如,我们将每一天不同时间的数据和对应的星期结合,试图发现是否人们在周五晚间的表现更像周六晚间的行为而非周日。其他例子还包括每天的时间和用户年龄、用户地域,操作系统和用户地域,性别和用户地域等。
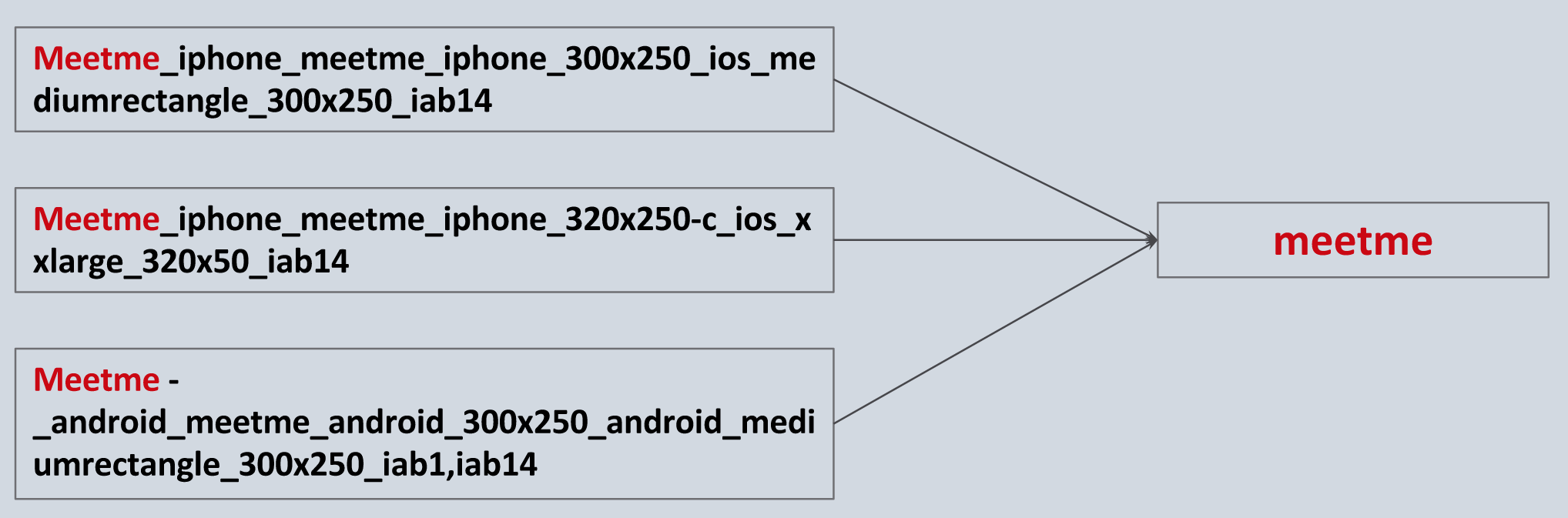
另外,大量数据是分类数据(categorical),并且不少都包含了更多的分级。但其实这些分级往往包含了同样的核心信息,因此可以被看作是同一个级别。我们减少了这样的分级数,将级数限制在最重要,最核心的信息。比如下面这组关于广告出现的app的数据中,左边的三组都包含了同一个关键词meetme,若不加处理,机器学习算法会将他们视为不同级别进行处理,而实际上它们只是手机型号的不同。因此我们将这些Impression都统一归为“meetme”这同一个维度的数据。
另外,有些数据有轻微缺失,比如地理坐标数据有4%的缺失,由于这些数据对于判断人群特征有帮助,我们决定留下,但同时机器学习算法无法很好地处理缺失数据,我们的做法是将缺失这一维度的数据统统删除。
但有的数据则出现大量缺失。一般处理这种情况有两种方法,一是直接全部舍弃,二是进行估算补充。在我们的项目中,几乎有一半数据缺失了性别这一维度。不少研究都证明性别在广告行为中的重要性,比如有一个进行了30多年的研究指出,女性会购买那些同时针对男女的广告产品,而男性则只会购买针对男性的广告产品。有鉴于此,我们决定使用机器学习对缺失的性别数据进行预测。
我们使用了随机森林,数据仅选择了描述用户和他们的设备的数据,排除了与广告和点击有关的数据。最终我们的模型包括了40个树,和最高20的深度。每个分支有4个变量。这个模型预测性别的准确度达到85%。
对于一般模型,我们使用了约7300万Impression数据。基于此,我们又分别拿出头发护理(HairCare)公司和运动酒吧公司的广告数据用于两个单独模型。一般模型的CTR是0.63%,我们选择的头发护理公司CTR为1.45%,运动酒吧为0.55%,正好在0.63%一上一下。
对于这两组具体广告项目的数据,我们又进一步按时间进行分割,形成训练数据组、验证数据组和测试数据组。所有的数据来自2016年9月1到22日,我将1到17日的数据作为训练数,剩下作为测试数据,各自占80%和20%。在训练数据中我进一步划分出验证数据组。我使用了一个随机分割,最终训练数据占60%,验证数据占20%。我希望用对这20%的验证数据进行一次验证的方式来替代对全部80%的训练数据进行交叉验证的过程。
预测CTR是一个二元分类问题,我们决定使用随机梯度下降法的逻辑回归。这样做的好处包括:高纬度下的稳健性(robustness),训练速度,可解释度,适当性(appropriateness),对于类不平衡性的潜在的稳健性。
对于逻辑回归下的类不平衡性问题,我们采取一个实验尝试解决。一个常用的方法是通过对主要的类(class)进行采样过疏(Undersampling)处理。也就是将一定比例的主要的类的数据丢掉,从而降低模型训练组类不平衡( class imbalance)的问题。但风险是可能因此导致训练的数据不够。
为了检查采样过疏对我们模型的影响,我们用不同程度的采样过疏进行了训练。一次对主要类别进行10%的采样过疏处理,一次是1%。
评估指标的选择。训练完模型后我们可以给模型输入新的bid request而模型会得出这个请求最终带来一个可以被点击的Impression的可能性。为了做出点击与否的预测,我们需要确定一个阈值,为此我们则需要决定我们要如何评估预测的质量。
所有预测两类结果的分类模型都会有四种情况:真阳性(TP),假阳性(FP),假阴性(FN)和真阴性(TN)。图示如下:
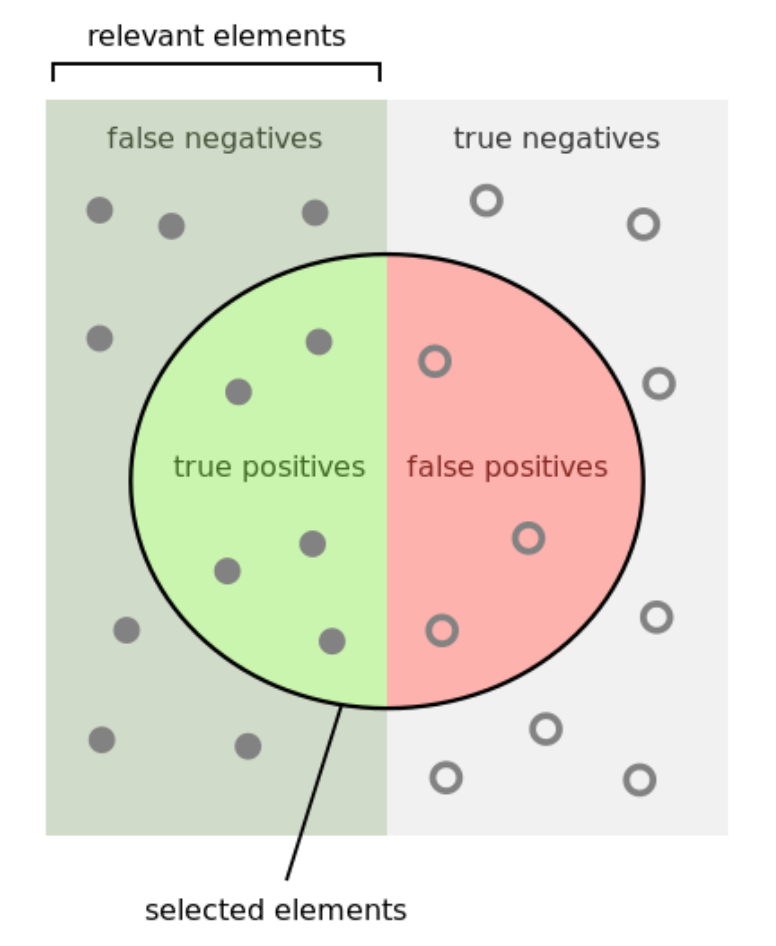
在移动广告的情境下这四种分别对应:
TP:Impression得到点击。也就是广告花费产生了回报。
FP:Impression未获点击。就是广告花费没有产生回报。
FN:输了的/没有竞价的request但得到了点击。
TN:输了的/没有竞价的request最终也没有得到点击。也就是钱很好的省下来了。
假设TP,FP,FN,TN分别代表各自对应情况的总数。那么他们就可以通过计算来衡量一个模型的准确度。
一个很明显的方法是准确率。由 (TP + TN)/(TP +FN + FP + TN)定义。但由于我们数据的极度的类不平衡性,这个方法很快被否决。另一个被否定的是特异性,或TN比率,定义为TN/(TN + FP),因为我们的焦点更多是关于点击而非未点击。
因此,我们的两个基本衡量方法是召回率(recall)和精准度(precision)。
召回率是由TP/(TP + FN)定义,也可以叫做TP比率。它回答了“你在所有的点击中获得了多少比例”的问题。高召回率可以被解释为对相关的广告机会利用的好。低召回率是抽象、假设层面的损失金钱;想做广告的公司没能将广告展示给他所能触及的尽可能多的受众。理论上召回率可以靠简单地买下所有bid request来最大化,但这样并不现实。
精准度是定义为TP/(TP + FP),回答了“所有买下的Impression中有多少比例转化成了点击”的问题。高的精度意味着钱花在了对的地方。反之则是花了大钱但只得到很少回报。
为了让AA的客户高兴,我们意识到需要让召回率和精准度有很好的平衡,从而最大化受众范围以及转化来的点击量。我想到两个评估模型的衡量方法:Fβ 分数和Precision-Recall 曲线下面积(AUPR)。
总的来说,Fβ是召回率和精准度的调和平均。它总在两者之间,但同时又更接近两者中较小的一个。而算数平均则永远居于两者正中。Fβ的公式如下
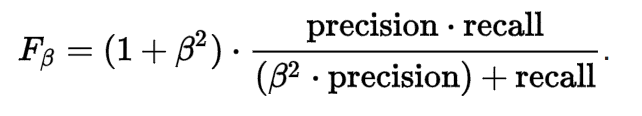
如公式所示,β的不同导致精度或召回率的不同权重。当β = 1,两者谁更小,就会更接近谁。当 0 ≤ β < 1,精准度被人为设置的更小,因此权重较召回率值大,当β > 1则相反。
鉴于我们希望优先考虑精准度,我们将β 定在0.5。我们需要在模型中找到最佳的F0.5值。
之前提到我们会进行采样过疏的操作,1%的采样过疏模型用于对头发护理公司的Impression数据进行训练,来预测其测试数据,从中得出的F0.5的值。我们也用一般Impression的数据训练的1%采样过疏的模型来预测头发护理公司的测试数据,同样得出一个F0.5分数。我们重复这种计算,得出如下数据:
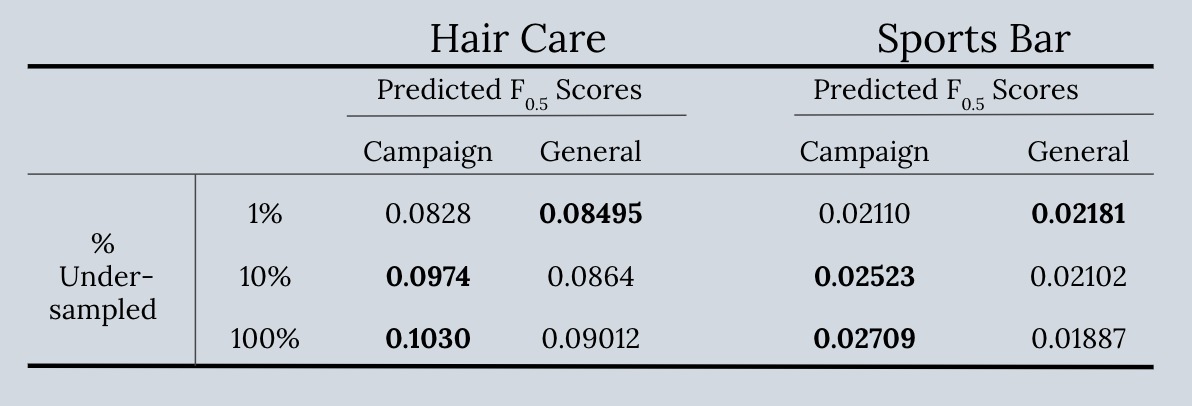
两组比较后,更好的F0.5值被加粗标注。有趣的是,随着采样过疏度减少,每个模型都有所提高。意味着逻辑回归在一定情况下对于极端的类不均衡来说是稳健的(robust)。具体情况可以对每个案例进行具体分析来进一步了解。
我们的模型比较结果如下:在使用F0.5值作为选择标准的情况下,鉴于所有模型都是使用拥有最低的样本复杂率的数据进行的训练,我们可以得出结论,为具体广告活动量身定做的模型比一般模型在预测点击概率上更加有效。
接下来我们想进一步研究我们的发现在商业应用上的潜力。我们想为每个模型计算以下值:
总花销(total spent):若AA将模型预测的会带来点击的bid request都竞价赢下,需要客户花费多少钱。
总共省下多少(total saved):如果AA没有竞价任何模型预测出不会带来点击的bid request,可以为客户省下多少钱?当然这个概念对于实际操作来说有点天真。
为了达到盈利,每个点击所需的“下游回报”:不同的模型会有不同的购买策略,是否选择更激进的策略需要更周全的思考,到底每个点击需要对应获得多少回报,才能实现盈利?这数字也与选择的不同策略有关。
投资回报(ROI):如果AA按照模型预测的买下所有会带来点击的requests,避开所有不会带来点击的requests,那么对于他的客户来说,其ROI是多少?如上所说,更激进的策略会带来更多的TP并因此提高毛利润,然而它也会带来更多FP。因此花出的钱和回报的钱的比例是更好的比较两种模型的方式。
将每个点击带来的下游回报用x表示,另外再引入一个变量:每1000次Impression的平均价格,用price表示。
相应的概念的方程如下:
1. total spent
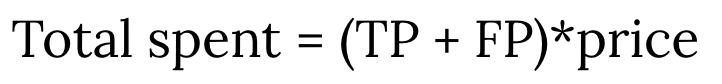
2. total saved
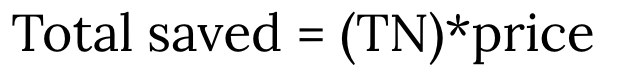
3. 为了达到盈利,每个点击所需的“下游回报”:

4. ROI:
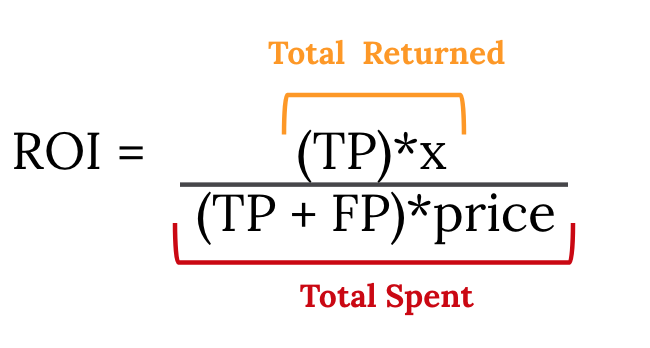
每个最佳模型的TP,FN,FP和TN以及上面四组值都列在下表中。其中ROI是在x等于两个模型中较大值的情况下计算得出。我们假设一个真的,单一的x是可以独立于任何模型存在的,而且为了便于比较,我们将它定在了这样一个值,从而让两个模型都可以实现盈利。
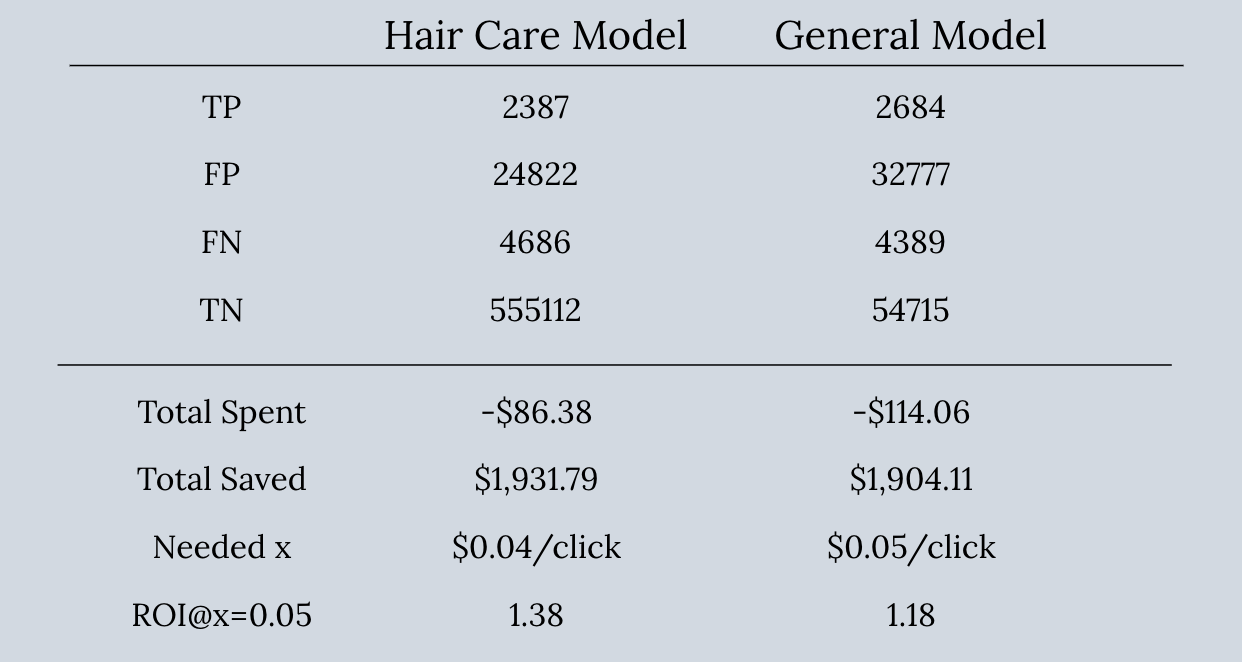
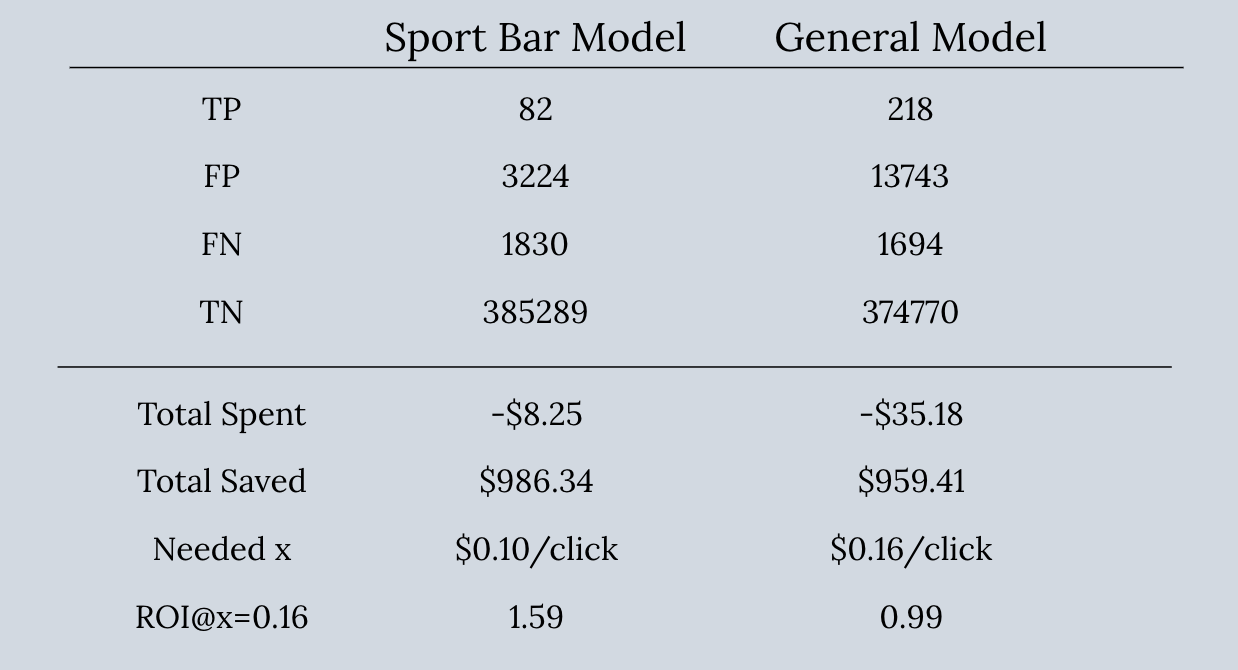
可以看出, campaign-specific模型,从商业角度看相对更保守和风险较低。另外,由于 campaign-specific模型的x值更低,当x未知时,公司更加可能使用campaign-specific模型。
总的来说,这个商业角度出发的对各类模型的分析证实了我们学术角度的分析发现。
(本文编译自技术博客Predicting clicks in mobile advertising——an experiment,仅代表作者观点。)
Kathryn Bryant 在布林茅尔学院取得数学专业博士学位。她是一个受过训练的拓扑学家,在研究地理数据的范式的过程中激发起了对数据科学的兴趣。她在科罗拉多学院使用R语言教授统计入门课程的过程中也加深了这一兴趣。

Paul Ton 是一名受过专业训练的软件工程师。他敬畏数据科学的理论基础,也欣赏用于解决实际问题的实践技巧。他永远乐于讨论关于数据的一切!

M. Aaron Owen在纽约大学取得进化生物学的博士学位,是福布莱特计划的成员。他对将自己的分析和科技能力用于行业内并对现实世界带来有意义的影响感到十分兴奋。

DT财经与纽约数据科学学院是战略合作伙伴。DT×NYCDSA 系合作开设的系列专栏。

数据侠计划是由第一财经旗下DT财经发起的数据社群,包含数据侠专栏、数据侠实验室系列活动和数据侠联盟,旨在聚集大数据领域精英,共同挖掘数据价值。申请入群请添加微信公号dtcaijing004并备注“数据社群”,合作请联系datahero@dtcj.com。

(了解更多有趣又有料的商业数据分析,欢迎关注DT财经微信公众号“DTcaijing”,下载“DT·一财”APP)
分享这篇文章到
2019-01-17

2019-02-15

2018-11-16

2018-12-28