
赚钱这事儿,如何放心交给机器打理?
2019-01-17

意见
反馈

回到
顶部

Jongerden & Fu 2018-03-09
为了更好地帮助人们选择自己的理想座驾,我们需要能够将个人需求与品牌及型号信息进行匹配的数据。
由于这种数据并不是公开可以获取的,只能从现有的汽车销售网站上提取。而这些网站上的数据,也代表着当今市场上正在交易的汽车的信息。我们使用Python的Beautifulsoup对一个非常流行的汽车网站进行爬取,获得了12000辆车、覆盖20种品牌和37个特征维度的数据集。我们之后搭建的推荐系统,推荐的车型也将来自上述范围。
我们首先用R语言、使用K近邻算法(K Nearest Neighbor)对缺失数据进行处理和补充。缺失最多的是油耗信息(8.6%缺失)和加速数据(6.9%缺失)。我们基于车价、汽车品牌和汽车类型,使用欧式几何距离法(Euclidean Distance)以及等于根号n的K值,通过K近邻算法进行了补充,并最终得到一个完整的数据集。由于K近邻算法是无监督机器学习算法,我们没法量化它的表现和准确度,尤其是在一个多维的解空间里(Multidimensional Solution Space)。
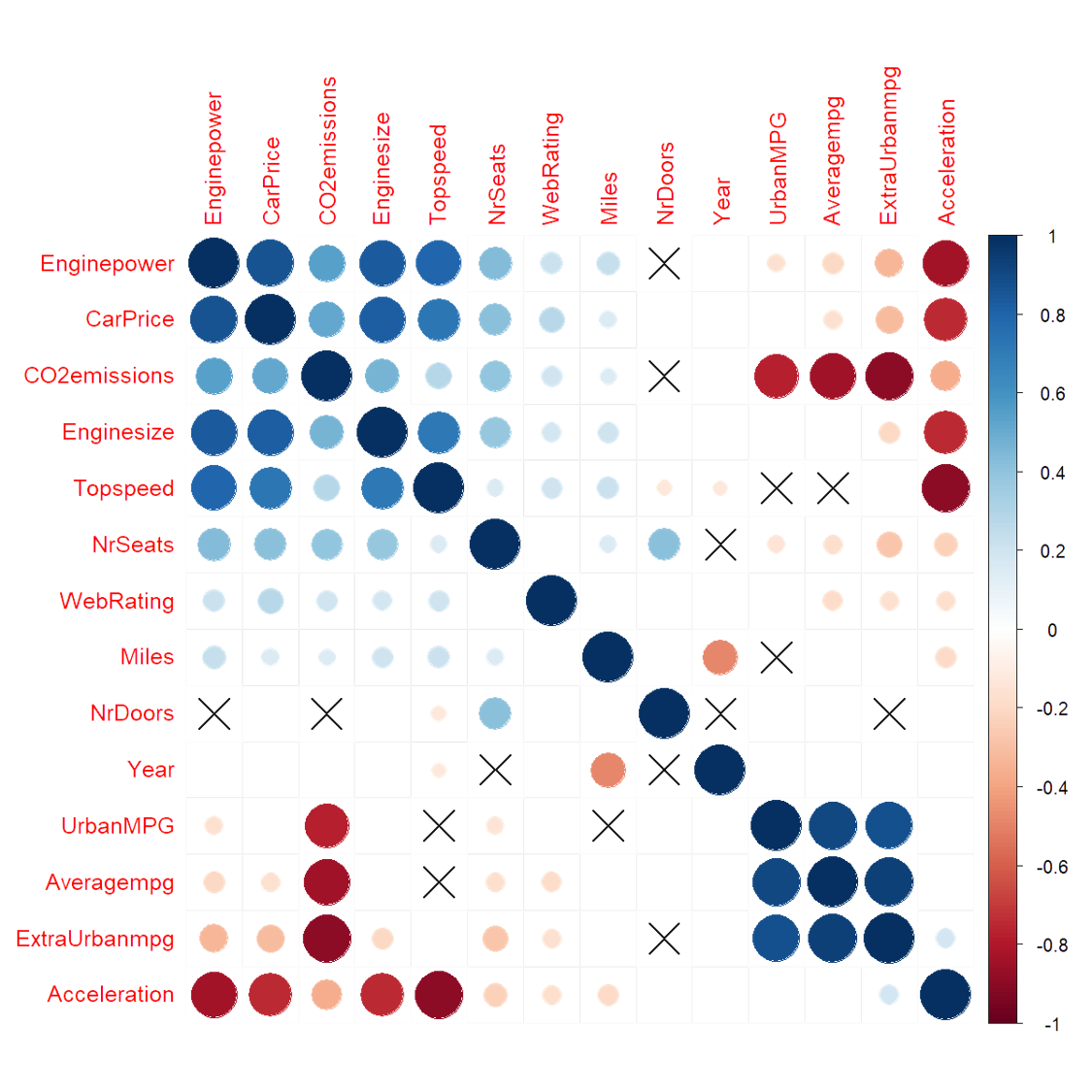
初步的数据分析显示出很有意思的相互关系。比如,车价和引擎型号有很强关联,高价位的汽车往往有更大的引擎。另外,数据显示,更贵的车往往更耗油。总的来看,不同维度的变量之间有很强的相关性,这让我们可以用各种机器学习算法来进行分析。
为了预测那些对潜在购车者来说很重要的特征,同时让我们的推荐平台能独立于外部数据源,我们使用机器学习算法对一些特定的特征进行了预测。
由于数据是通过特定方式收集(比如,设计相似的汽车会被放置在数据组的同一个类别下,因为在爬取时它们的数据收集是按照品牌顺序进行的),数据集中存在序列相关(Serial Correlation)现象。为了消除序列相关,我们在使用机器学习算法分析数据前,对数据组的次序进行随机排列。另外,为了验证效果,我们将数据组按照4比1的比例分成一个训练集和一个测试集。
首先,我们使用与车价高度相关的特征,搭建了一个多元线性回归模型。得出的R调整平方值(使用测试集计算得出)为0.899。在对预估模型进行Breusch-Godfrey测试后,观测到数据集是按照汽车产商和型号排列,检测到了序列相关性关系。为了解决这个问题,我们使用了开头提到的方法进行处理。另外,残差还发现存在异方差性,意味着残差中,对于不同车价来说,方差并不均等。尽管这不符合Gauss Markov假设中的一个最优线性无偏估计,但检查模型的残差图(Residual Plot)并未发现异方差性很高的残差,因此这个模型可以成立。
其次,我们使用了多元线性回归模型及前向逐步选择法(Forward Stepwise Selection)。这个算法将每个可能的模型与一个包含所有特征的模型进行比较,并选出贝叶斯信息量(Bayesian Information Criterion)最低的最佳组合。得出的R调整平方值(使用测试数据集计算得出)为0.914。
为了进一步提高线性模型的表现,我们使用一个预先设定的λ来代表车价,并对这个变量执行Box-Cox变换。Box-Cox变换是一种常见的数据变换,用于连续的响应变量不满足正态分布的情况,变换之后,可以一定程度上减小不可观测的误差和预测变量的相关性。经过Box-Cox变换,我们的数据更接近正态分布。这个模型得出的R调整平方值为0.9,与第一个手动调整的多元线性回归模型相比,并没有太多提升。
接下来,我们使用收缩方式,或称为正则化(Shrinkage/Regularization Method)来提高前面模型得到的数据。传统的收缩方式(Lasso回归和岭回归)在处理包含与因变量有强相关性的多元变量的数据集时,存在缺陷。假如使用Lasso回归,大多数系数会被减至0,但其实他们可能对结果有很强的解释力。而Elastic Net模型可以通过引入一个额外的超参数来平衡Lasso回归和岭回归,进而克服上面提到的问题。
此外,第二个引入的超参数则用于确定模型的均方差和复杂性之间的平衡。为了确定最佳的超参数,进而将均方差减小到最小,同时保证模型是最简单的,我使用了10折交叉验证。得出的R调整平方值为0.9218。
最后,为了进一步提升预测准确度,我使用了提升树模型(Gradient Tree Boosting Model)。它由7000个决策树组成,根据超参数的交叉验证所得的平均数,决策树的深度(Interaction Depth)等于4,收缩率(Shrinkage Factor)等于0.1。而它的R调整平方值十分惊艳,为0.9569,也就是说,我们测试的所有模型中,提升树模型拥有最强的预测能力。
不过即便提升树模型预测能力最强,人们依然更喜欢简单的模型。而鉴于简单的多元线性回归模型表现良好,简单的线性回归模型将会用于我们的推荐平台。
能够预测汽车价格和其他有趣的特征,可以在推荐汽车时为用户提供更多的信息。
我们的推荐基于一个基本假设:拥有相同偏好的用户做出的打分是相似的。这也意味着,如果一个人喜欢一辆特定的汽车的所有特征,那么他就在整体上喜欢这辆车。
为了找到符合某一名用户需求的车,首先需要找到与他拥有同样需求的其他用户,并将这些用户选择的对应的车型进行合并。在对这名用户与其他用户比较时,使用了K近邻算法,距离由皮尔逊相关系数或余弦相似性来确定。当这些相似用户被确定,他们对汽车的打分会被整合,并基于此为新用户做出推荐。这个过程被称为基于用户的协同过滤(User Based Collaborative Filtering)。
基于用户的协同过滤是一种半监督的机器学习技术,使用训练数据集的评分矩阵中的特定项来确定测试评分矩阵中的不确定的项。因此,我们可以评断推荐的准确度。我们使用一个7个值已确定的10折交叉验证,通过观察它的ROC和PR曲线(Precision/Recall Graphs)的平均值来评估推荐的表现情况。
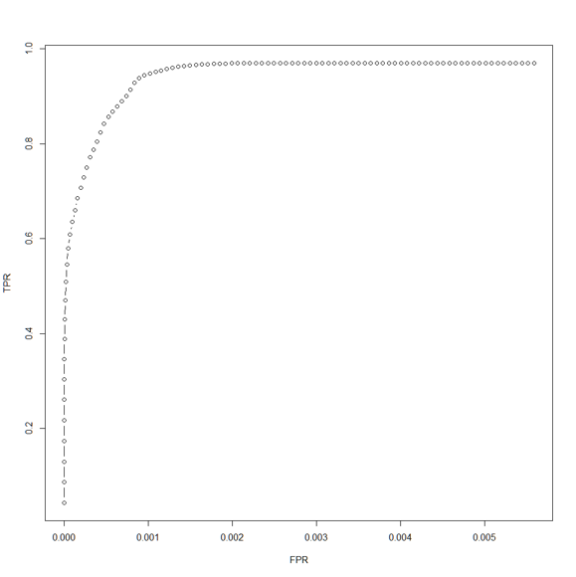
ROC曲线显示了True Positive (真正,对应y轴)和False Positive (假正,对应x轴)的关系。ROC的结果显示,多数推荐是正确的,仅有一小部分的False Positives(也就是假的预测)。ROC曲线向左上角靠近,说明这个模型的预测比较准确。
而PR曲线则显示了准确率(搜索结果到底有多大帮助)以及召回率(结果有多完整)之间的关系。从图中可以看出,对于一小部分推荐,准确度很高;然而,随着召回率提高,准确率趋向于0。
我们可以得出结论,这个模型在靠近图形右上角(代表着完美的模型)的时候表现良好。另外,将召回率限制在最多10个推荐的时候,准确率的降低会得到遏制。
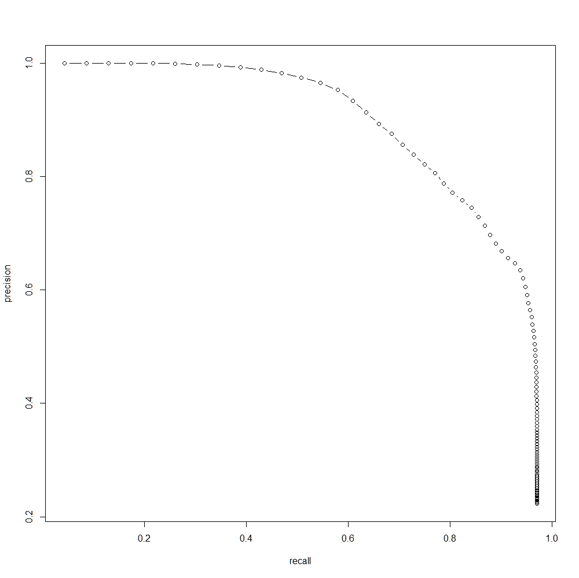 (图片说明:PR 曲线)
(图片说明:PR 曲线)
基于这个模型以及用户对车的具体需求,我们的推荐平台给用户推荐了10个汽车品牌以及相应的型号。
通过将推荐模型和机器学习模型结合,我们可以搭建一个交互界面(点击查看),当用户输入信息,比如他期待的汽车引擎马力、汽车类型等,系统就可以做出推荐。这些用户输入信息可以通过下拉菜单以及勾选等方式手动控制。此外,你还可以用一句话描述你的理想座驾,而推荐模型则会基于此为你推荐10辆你可能喜欢的汽车,它们的车价、排气量、油耗以及图片等信息也会展示出来,供用户进行简单比较。
当用户勾选“喜欢”,界面会重新将用户带到可以进行购买的网页。另外,用于推荐的信息以及用户喜欢的车的信息将在app外部存储。
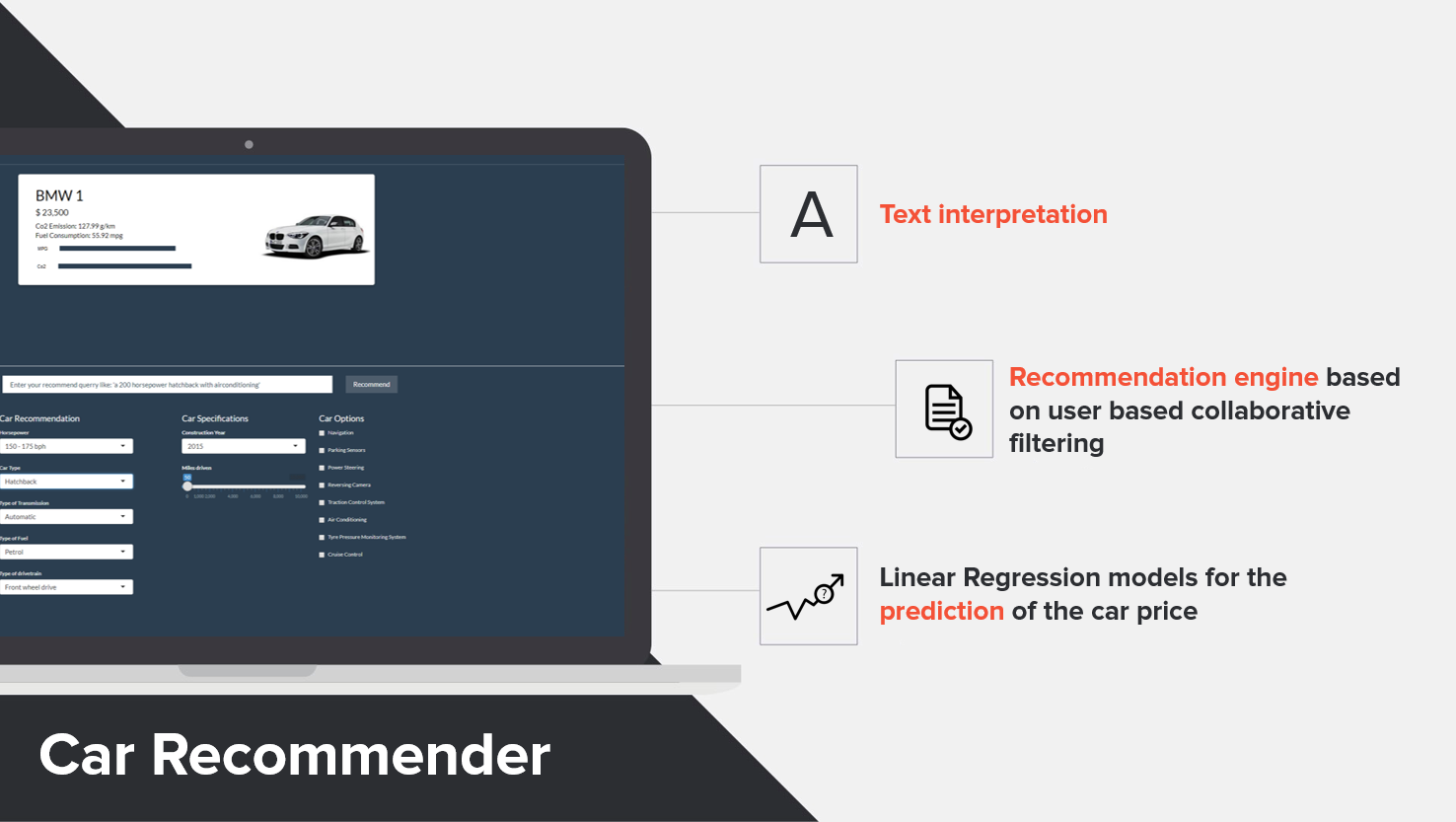
(图片说明:推荐系统的可视化界面截图)
总之,这个推荐应用使用了基于用户的协同过滤以及回归技术,以实现准确度地基于一些特定的汽车特征来为用户推荐汽车品牌和型号的功能。性能验证显示,推荐算法和回归模型都表现良好,成功组成了一个可靠的推荐平台。

Steven Jongerden毕业于代尔夫特理工大学,获得航空航天工程专业本科学位,政策分析和工程学硕士学位。他现在是荷兰凯捷管理顾问公司的一名数据科学咨询师。Steven在纽约数据科学学院进修,提升了自己机器学习和大数据分析的技能。

Huanghaotian Fu毕业于纽约大学,拥有数学和经济学硕士。目前在美国斯蒂文斯理工攻读金融分析硕士。他于2017年暑期完成纽约数据学院的培训
DT财经与纽约数据科学学院是战略合作伙伴。DT×NYCDSA 系合作开设的系列专栏。

数据侠计划是由第一财经旗下DT财经发起的数据社群,包含数据侠专栏、数据侠实验室系列活动和数据侠联盟,旨在聚集大数据领域精英,共同挖掘数据价值。申请入群请添加微信公号dtcaijing004并备注“数据社群”,合作请联系datahero@dtcj.com。

(了解更多有趣又有料的商业数据分析,欢迎关注DT财经微信公众号“DTcaijing”,下载“DT·一财”APP)
分享这篇文章到
2019-01-17

2019-02-15
2018-12-11

2018-11-16