
创业者注意了!大数据教你如何在众筹网站上成功融资
2018-12-29

意见
反馈

回到
顶部

2018-12-03
一年一度的维密大秀又要来了!每年的维密大秀从试镜到选定模特,再到彩排、录制、播出,可都会获得无数时尚圈人士和美好肉体爱好者的目光和热议,究竟维密大秀的宠儿们背后有怎样的秘密?我分析了1995年以来的走秀记录,用数据来为你揭秘!

维多利亚的秘密时尚秀从1995年开始举办,梦幻炫目的造型和独到的商业化策略十七迅速在时尚产业立足。能参加走秀是许多模特自童年开始就拥有的梦想,而佩戴Fantasy Bra,进行开秀和闭秀,成为一名维密天使更是令人荣耀!
通过这次数据分析,我想要探究的问题主要有:
话不多说,我们直接进入正题吧!
我在Wikipedia(维基百科)上找到了两个页面,第一个页面“Victoria's Secret Fashion Show“中有3个数据表格提供了我们想要的信息,分别是:
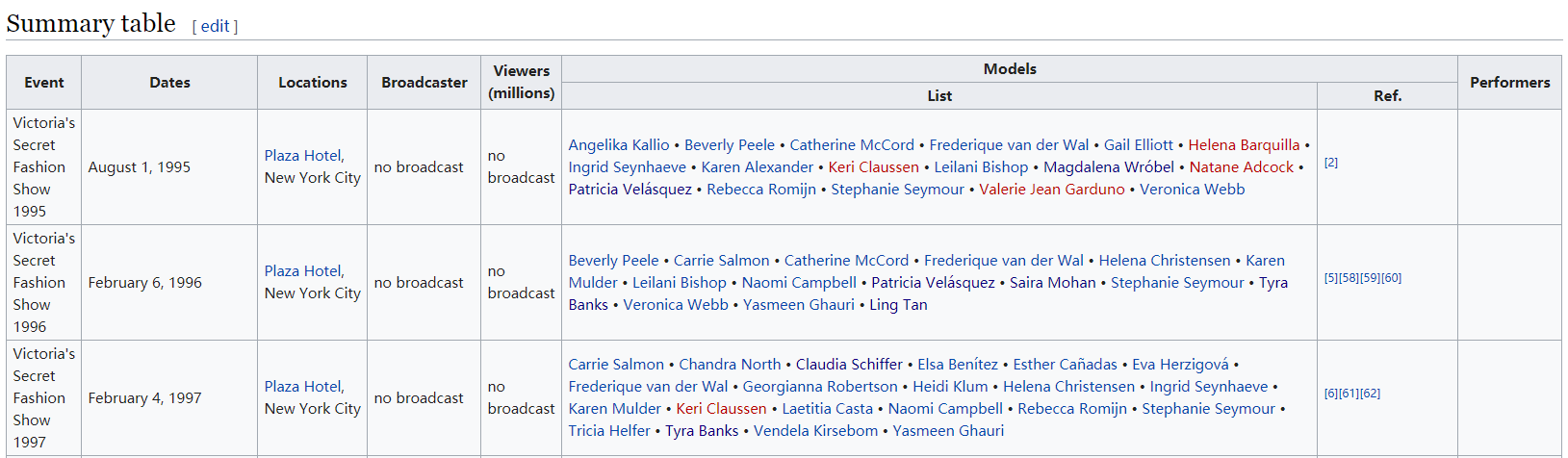
1.记录了每年大秀的时间、地点、参加模特、演出者等信息的summary table
2.记录了每年Fantasy Bra的佩戴模特、模特国籍、bra价值的等信息的表格

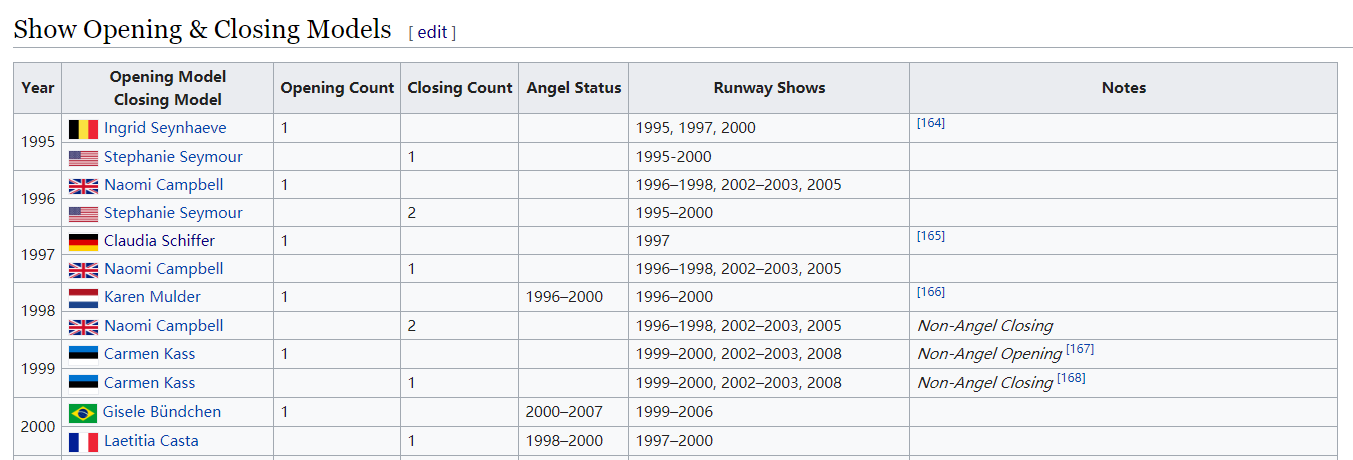
3.记录了每年开秀、闭秀模特的表格
在第二个Wikipedia页面“List of Victoria's Secret models“中,有两个表格分别提供了维密天使、参加维密大秀的非天使模特的信息,表格部分截图如下:
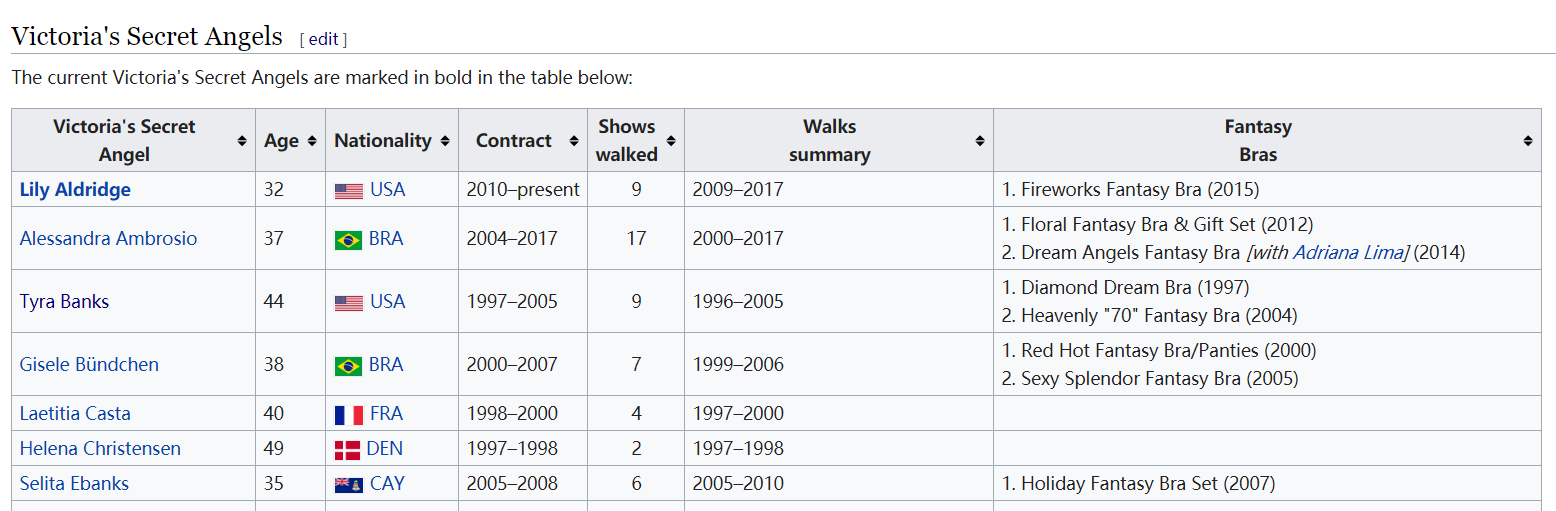
4.维密天使的信息表格
5.参加维密大秀的模特(不包括维密天使)的表格

对于这五个表格,我使用了scrapy包,自行搭建了5个爬虫对想要的信息进行抓取,然后以csv格式进行存储。以第一个表格summary table为例,我想要获取的列分别是:Event, Locations, Models.
Summary table的Spider代码如下:
from scrapy import Spider
from summary.items import SummaryItem
class SummarySpider(Spider):
name = 'summary_spider'
allowed_urls = ['https://en.wikipedia.org']
start_urls = ['https://en.wikipedia.org/wiki/Victoria\'s_Secret_Fashion_Show']
def parse(self, response):
rows = response.xpath('//*[@id="mw-content-text"]/div/table[2]//tr')
event_patterns = ['./td[1]/a/text()','./td[1]/text()']
location_patterns = ['./td[3]//a/text()','./td[3]/text()']
for row in rows:
for event_pattern in event_patterns:
Event = row.xpath(event_pattern).extract_first()
if Event:
break
for location_pattern in location_patterns:
Locations = row.xpath(location_pattern).extract()
if Locations:
break
Models = row.xpath('./td[6]/div/ul//a/text()').extract()
Performers = row.xpath('./td[8]//a/text()').extract()
item = SummaryItem()
item['Event'] = Event
item['Locations'] = Locations
item['Models'] = Models
item['Performers'] = Performers
yield item
在这里需要注意的是,原网页中Event和Locations列的数据格式比较复杂,有文本和超链接的多种混合形式,为了尽可能不丢失数据,我们需要多试几次,把所有pattern的xpath记录下来,以便在爬取的时候遍历它们。
从Fantasy Bra表格抓取年份、bra名称、模特名字、bra价值等信息的Spider代码如下:
from scrapy import Spider
from fantasy.items import FantasyItem
class FantasySpider(Spider):
name = 'fantasy_spider'
allowed_urls = ['https://en.wikipedia.org']
start_urls = ['https://en.wikipedia.org/wiki/Victoria\'s_Secret_Fashion_Show']
def parse(self, response):
rows = response.xpath('//*[@id="mw-content-text"]/div/table[3]//tr')
for row in rows:
year = row.xpath('./td[1]/text()').extract_first()
name = row.xpath('./td[2]/text()').extract_first()
model_name = row.xpath('./td[3]/a/text()').extract()
model_country = row.xpath('./td[3]/span/a/@title').extract()
value = row.xpath('./td[4]/text()').extract()
in_show = row.xpath('./td[5]/text()').extract_first()
item = FantasyItem()
item['year'] = year
item['name'] = name
item['model_name'] = model_name
item['model_country'] = model_country
item['value'] = value
item['in_show'] = in_show
yield item
抓取开秀、闭秀记录的Spider代码如下:
from scrapy import Spider
from openclose.items import OpencloseItem
class OpencloseSpider(Spider):
name = 'openclose_spider'
allowed_urls = ['https://en.wikipedia.org']
start_urls = ['https://en.wikipedia.org/wiki/Victoria\'s_Secret_Fashion_Show']
def parse(self, response):
rows = response.xpath('//*[@id="mw-content-text"]/div/table[5]//tr')
name_patterns = ['./td[2]/a/text()', './td[1]/a/text()']
country_patterns = ['./td[2]/span/a/@title','./td[1]/span/a/@title']
for row in rows:
for name_pattern in name_patterns:
model_name = row.xpath(name_pattern).extract_first()
if model_name:
break
for country_pattern in country_patterns:
model_country = row.xpath(country_pattern).extract_first()
if model_country:
break
item = OpencloseItem()
item['model_name'] = model_name
item['model_country'] = model_country
yield item
抓取维密天使名字、国籍的Spider代码:
from scrapy import Spider
from ModelList.items import ModellistItem
class ModellistSpider(Spider):
name = 'modellist_spider'
allowed_urls = ['https://en.wikipedia.org']
start_urls = ['https://en.wikipedia.org/wiki/List_of_Victoria%27s_Secret_models']
def parse(self, response):
rows = response.xpath('//*[@id="mw-content-text"]/div/table[1]/tbody//tr')
for row in rows:
model_name = row.xpath('./td[1]//a/@title').extract_first()
model_country = row.xpath('./td[3]//a/@title').extract_first()
item = ModellistItem()
item['model_name'] = model_name
item['model_country'] = model_country
yield item
抓取参加过维密大秀的非天使模特信息的代码如下:
from scrapy import Spider
from modellist2.items import Modellist2Item
class modellit2Spider(Spider):
name = 'modellist2_spider'
allowed_urls = ['https://en.wikipedia.org']
start_urls = ['https://en.wikipedia.org/wiki/List_of_Victoria%27s_Secret_models']
def parse(self, response):
rows = response.xpath('//*[@id="mw-content-text"]/div/table[2]/tbody//tr')
for row in rows:
model_name = row.xpath('./td[1]/span/a/text()').extract_first()
model_country = row.xpath('./td[2]/a/@title').extract_first()
item = Modellist2Item()
item['model_name'] = model_name
item['model_country'] = model_country
yield item
数据清洗
获得了我们想要的数据后,直接在jupyter notebook中将csv文件导入进行清洗,在这个过程中我运用到了numpy,pandas,以及正则表达式这几个工具包。
在这里我将对每个表格的数据清洗过程分别进行简要的概括,具体细节和操作代码可以移步至jupyter notebook中查看。
1.Summary Table
原始数据:

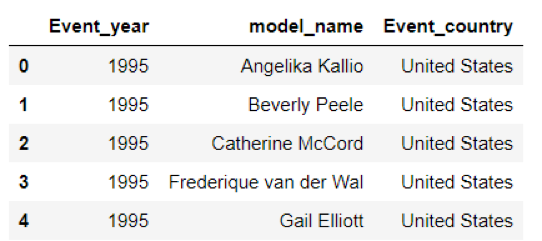
原始表格中每一年的大秀为一条记录。Event列的有效信息只有年份,因此我们新建一列Event_year加在表格中。Locations列的字符串既有“地点+城市“,又有”城市+国家“的组合,比较混乱,我们根据实际情况新建一列Event_country,手动赋值,用于记录每年大秀的举办国家。Models这一列的情况更为复杂,每一年参加走秀的所有模特名字都被记录在1个单元格内,然而我们想要进行的是建立在模特个体层级上的数据分析,因此需要对模特名字的列表进行拆分,使得每一年每一个参与走秀的model都占据一行记录。
清洗后的数据:
2.开秀/闭秀记录
原始数据:

网页中的开秀和闭秀按照时间顺序被记录在了一起,原始数据表格中index为奇数的行是开秀模特,偶数行为闭秀模特,大秀时间从1995年到2017年(其中2004年没有走秀,而是以巡回展出的形式呈现)。我将开秀和闭秀分离成两个dataframe,并添加上年份一列。
清洗后的开秀记录:
清洗后的闭秀记录:
最后我们将开秀和闭秀的记录合并到第一步的summary table中。创建新的列open,若该模特在该年的走秀中担任开秀,则open取值为1,否则为0:
#编写for循环,查找历年走秀记录中的每一个(模特,年份)组合是否出现在开秀记录中
for i in range (0,777):
if (df_model_summary['Event_year'][i], df_model_summary['model_name'][i]) in [(df_open['year'][i], df_open['model_name'][i]) for i in range(0,22)]:
df_model_summary['open'][i] = 1
同样的方法再创建close列,最终得到summary table如下:
3.Fantasy Bra
原始数据:

我们将爬取下来的原始数据中的换行字符去掉,year列的数据类型改为整数;

2014年维密推出了一对fantasy bra,由两位模特佩戴,但是数据中只用一行记录了下来,在这里我们用之前拆分模特名字的方法处理一下,将2014年的记录分成两行,美味模特占一行,然后手动修正国籍、bra价值,使2014年的记录以如下形式呈现:

清洗后的Fantasy Bra表格:
在summary table新建一列,记录fantasy bra的佩戴情况,使用的方法与之前创建open列和close列的相同,得到新的summary table:
4.维密天使表格
导入原始数据(部分截图):
这个表格相对干净一些,进行的数据处理操作有:去掉全部为空的第一行;去掉了第11行模特名字中多余的字符串‘(model)‘;补齐了在数据爬取过程中丢失的一个模特国籍;创建一列angel,用于记录模特是否为维密天使,对这个表格中所有的模特赋值为1。
清洗后数据如下:

5.参与走秀的非天使模特表格
导入原始数据(部分截图):
这里除了丢失的模特国籍数据的处理过程,其他都与上一个天使表格的操作过程类似。
至于国籍丢失的问题,我查看了原网页,是由于原网页将相邻的两个同国籍模特的两个国籍单元格合并成一个导致的,例如下图:

在这个例子中,我们抓取下来的数据,只有第一行Ana Beatriz的国籍没有丢失,后面两个国籍被合并的模特,在原数据表格中的国籍都是NaN
写一个循环解决这个问题就好了:
for i in range (0,236):
if model_list_2.model_country[i] is np.nan:
model_list_2.model_country[i] = model_list_2.model_country[i-1]
得到修复好的非天使模特列表:
最后将天使和非天使列表连接在一起,得到所有走秀的模特列表。
至此,我们得到了下一步数据可视化需要的两个表格:
数据清洗过程中,我对DataFrame应用了很多次for loop,后来经过纽约数据科学院的老师点拨,如果改用pd.dataframe的apply方法来处理会有更高的效率。
数据可视化
首先还是从导入数据开始,导入历年走秀记录(df_show)和模特列表(df_model)两个表格。
这里发现了一个小问题。对于df_show,我想要进行模特个体水平的aggregation,计算每个模特参加走秀的总次数,最终得到了278个模特;但是df_model有273个模特,为了发现问题,这里我将两个表格中得到的模特名单merge了一下:
temp = pd.merge(df_show_count, df_model, how = 'left', on ='model_name')
temp.loc[temp.model_country.isnull(),:]
下表这些名字,都是在df_show中有记录,但在df_model中查找不到的。倒数三行是从网页中抓取出的特殊注解字符,删除它们即可;其他的名字查找不到的原因,经过我的排查,大部分是含有特殊字母的模特名字在两边表格中的拼写方式没有统一(比如名字中含有字母é的名字,在另外的表中用的是e来进行拼写);好在这里没有出现大小写不统一的情况,如果有的话,先把两表中所有的名字都改成lower case,再去匹配两个表,就可以避免mismatch的情况啦。

对于特殊字符(就是像é这样含有上标的字母)拼写不统一的情况,我用的方法就是在两边的表格逐个查询、逐个修改……真的山穷水尽了……累哭我了!
解决了名字拼写的问题,我们以df_show为基础,对每个模特的走秀次数、开秀次数、闭秀次数、佩戴fb次数进行计算,然后将计算结果merge到df_model中,得到model_summary表格(部分截图如下):
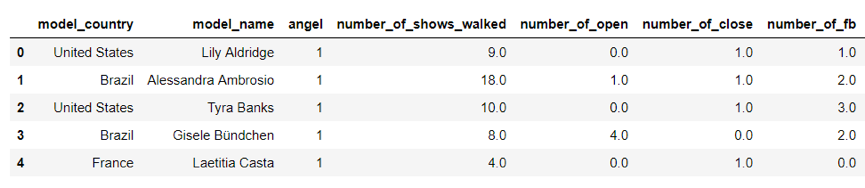
终于可以进入正经的可视化阶段了!这个部分我用到的主要是matplotlib和seaborn两个工具包。
Q1. 谁是参加过最多次走秀的模特?
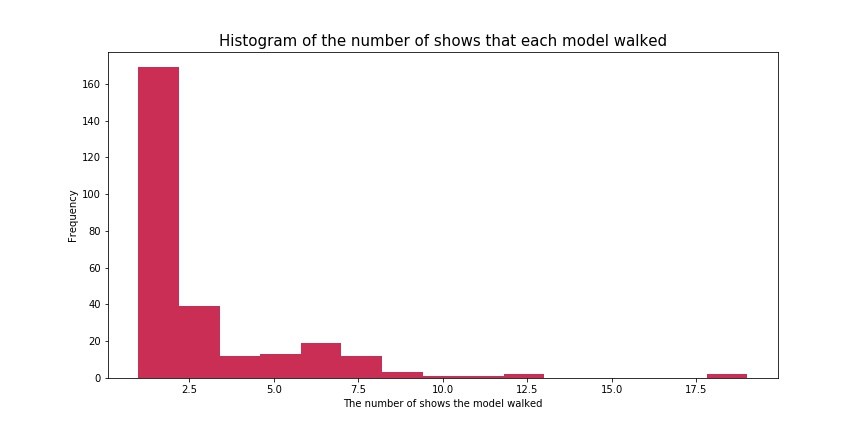
先来看一下每个模特走秀总次数的频数分布直方图,绝大部分模特都只走过1次秀,极少数模特走过最多19次维密大秀,可以说是元老级别的模特了!
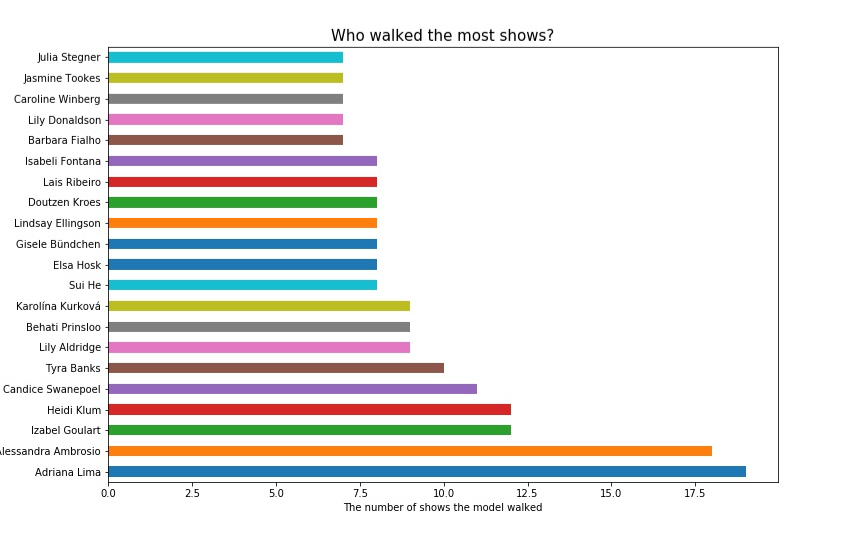
这位参加过19次维密秀的模特就是Adriana Lima, 紧跟其后的是在2017年完成人生中第18次也是最后一次维密秀的Alessandra Ambrosio,何穗是进入上图排行榜的唯一中国模特,她将在今年迎来自己的第八次维密秀。
Q2. 哪位模特开秀/闭秀/佩戴Fantasy Bra的次数最多?
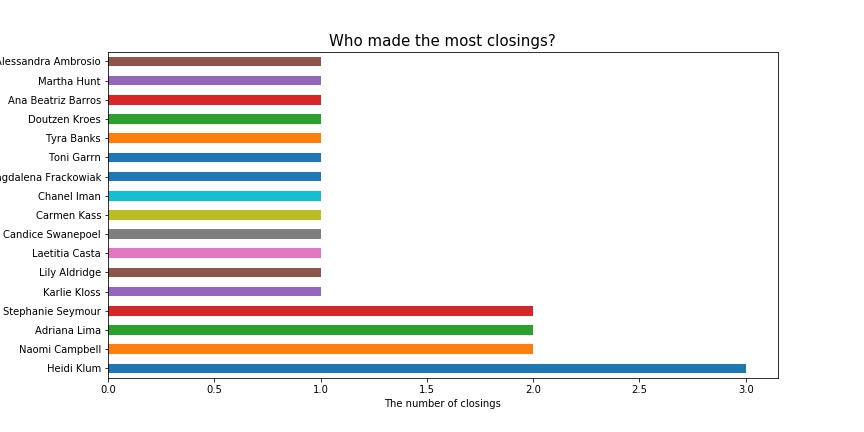
维密的元老级天使Heidi Klum为维密秀开秀3次,是独一无二的榜首。
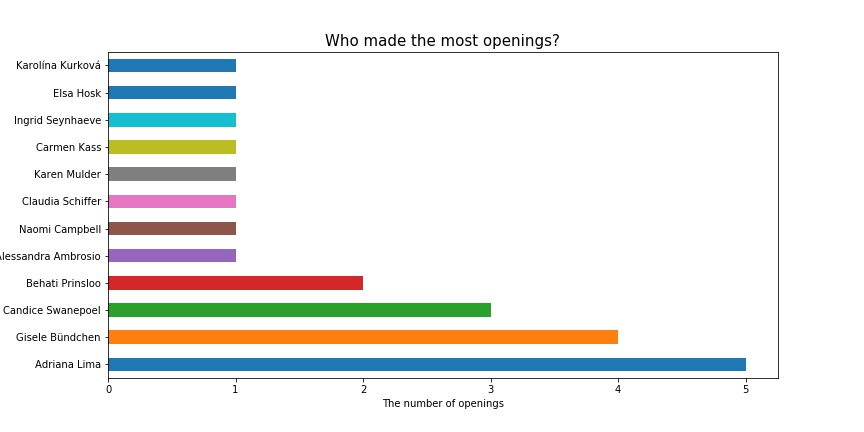
相比于开秀,闭秀的分配集中在了更少的几个模特当中。走了19年维密秀的Adriana Lima闭秀次数最多,高达五次。
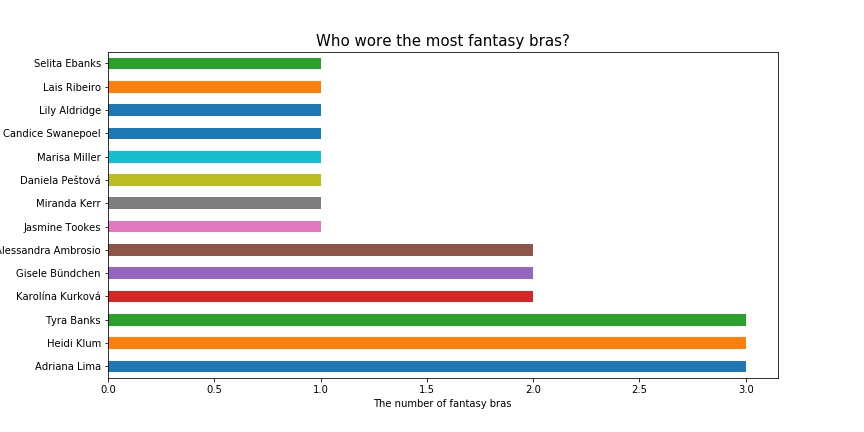
至于Fantasy Bra的分配,佩戴次数最多的三位分别是Tyra Banks, Heidi Klum, Adriana Lima,都是开秀/闭秀经验丰富的模特,维密真的很宠她们!
Q3. 维密天使都来自于哪些国家?
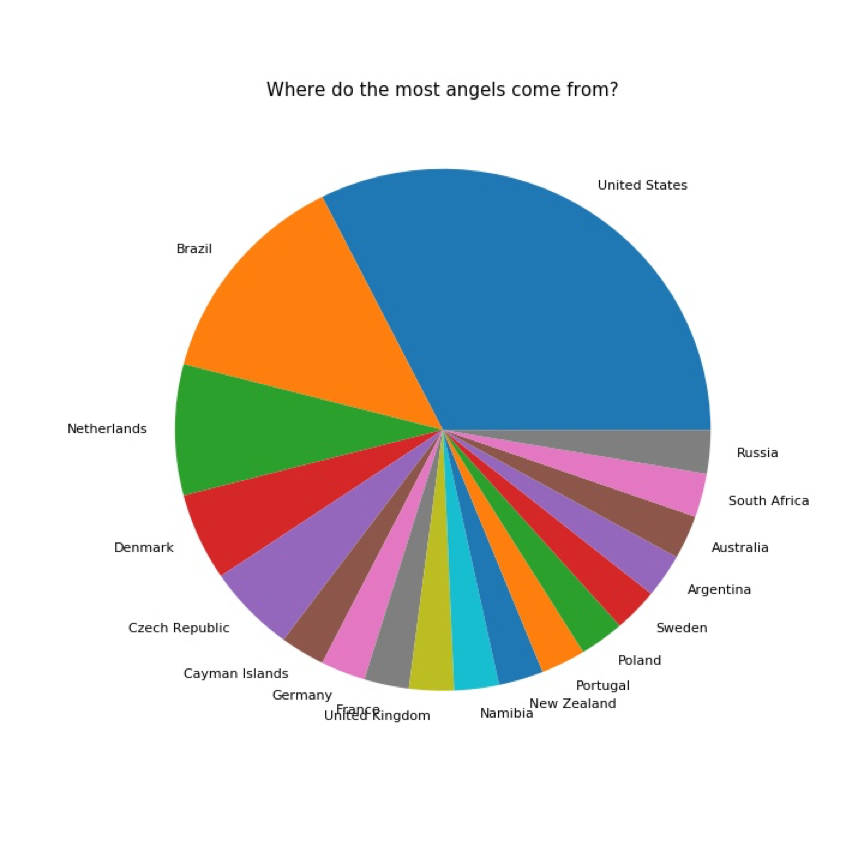
维密天使中,来自美国的占比最多,超过了四分之一;巴西和荷兰紧随其后,与美国组成前三,这三个国家的维密天使占据了超过半壁江山。
Q4. 开秀/闭秀/佩戴Fantasy Bra最多次的模特来自于哪些国家?
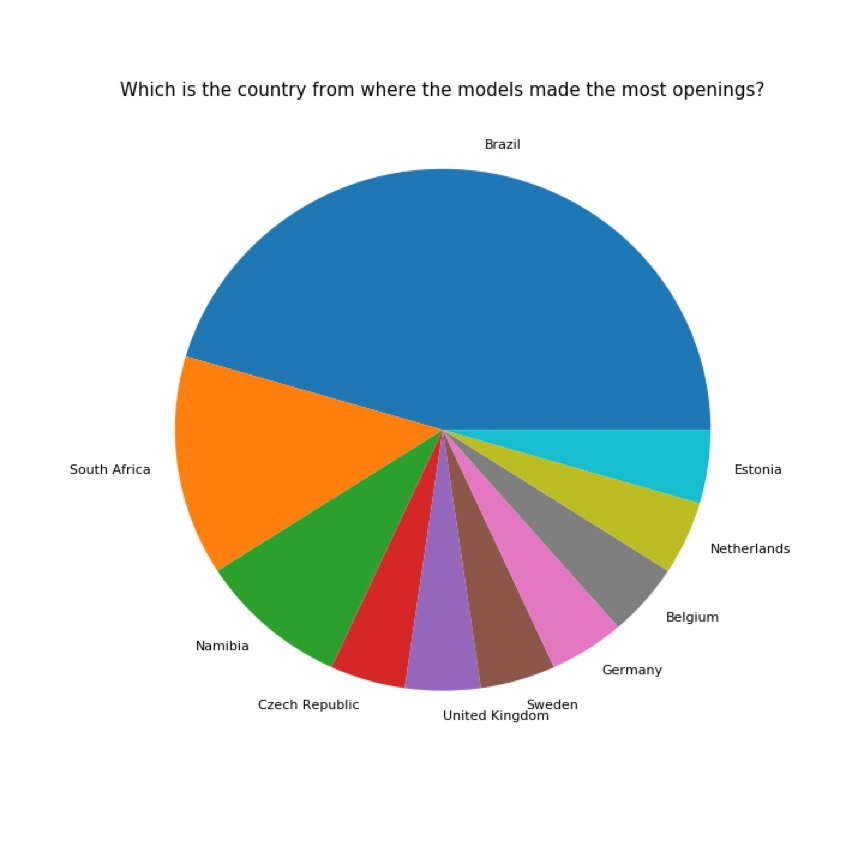
巴西的模特被选为开秀模特的次数最多,其次是来自南非的模特;令我惊讶的是,维密天使人数最多的美国,还没有模特开过秀。
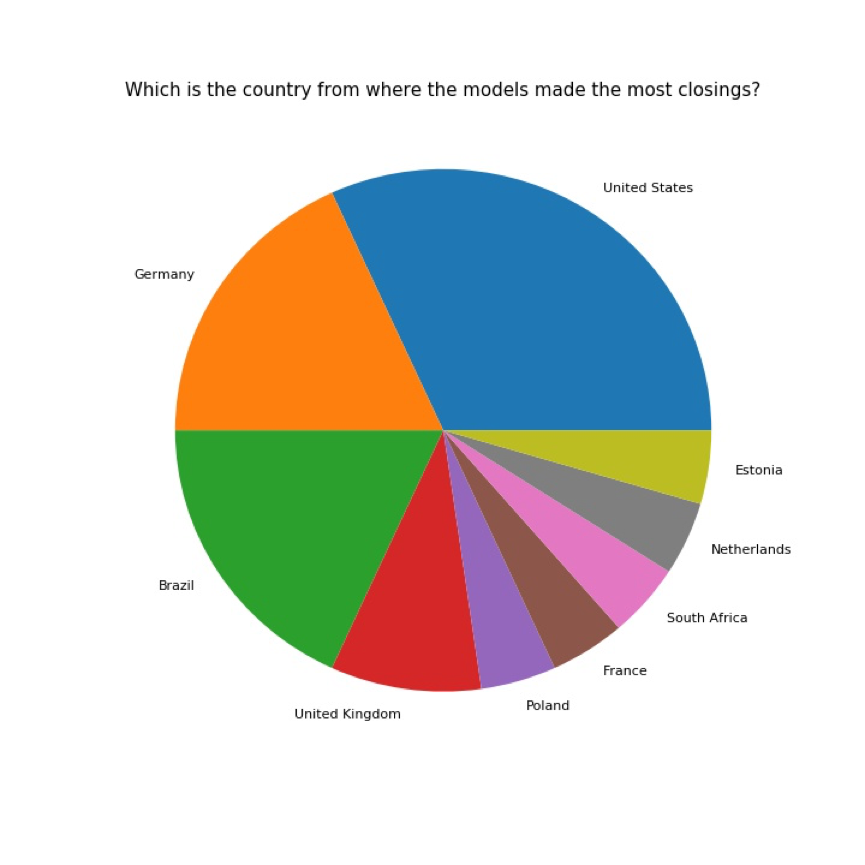
看到闭秀分配这张图,前面的疑虑好像得到了解答哈哈哈……从未开过秀的美国模特,获得了最多次的闭秀任务。闭秀次数排在第二的是南非,同样地,来自这个国家的模特也没有开过秀。

到了Fantasy Bra这里,前两位分别是巴西和美国。巴西是开秀次数top1,美国是闭秀次数top1。【很好,有点雨露均沾的意思……
Q5. 成为维密天使与否与参加大秀的次数是否有关?
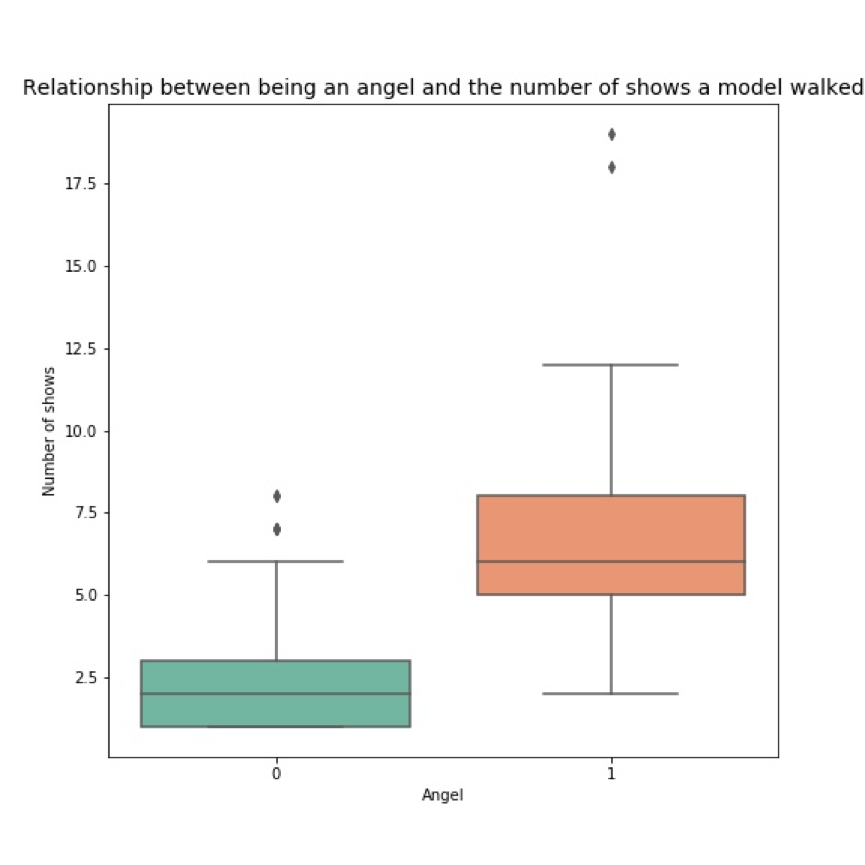
我对天使和非天使的走秀总次数分别绘制了箱线图,肉眼可见的分别,维密天使的走秀从总次数比非天使要多出很多。
再跑一个2 sample t-test 验证一下:
#跑一个2 sample t-test 验证我们的猜想
number_of_shows_walked = model_summary['number_of_shows_walked']
shows_non_angel = number_of_shows_walked[model_summary['angel']==0]
shows_angel = number_of_shows_walked[model_summary['angel']==1]
shows_non_angel = shows_non_angel.dropna()
shows_angel = shows_angel.dropna()
from scipy import stats
stats.ttest_ind(shows_non_angel ,shows_angel)
Ttest_indResult(statistic=-13.017789081684617, pvalue=2.3704995718195955e-30)
P值接近0,说明非天使模特和天使的走秀次数差异真的是非常大了!【不过这也不能说明走秀次数多就是成为天使的原因……有一些计量经济学基础的朋友都懂的
Q6. 开秀/闭秀/佩戴Fantasy Bra与参加大秀的次数是否有关?这些模特一定都是维密天使吗?
a.开秀
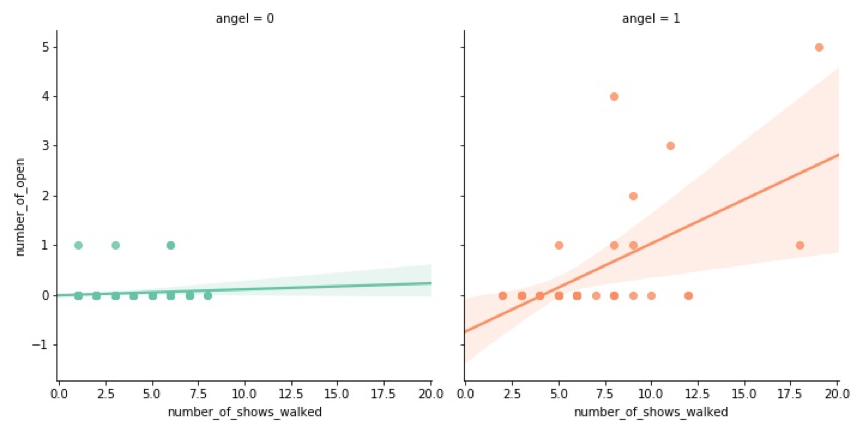
左半边绿色部分说明,非天使开秀的例子是有的,但是这些模特最多只开过一次秀,她们分别是Carmen Kass,Claudia Schiffer,Ingrid Seynhaeve,Naomi Campbell,值得注意的是Claudia Schiffer在她仅有的一次走秀历史中,就担任了开秀的任务。
右半边橘色部分说明在天使中,走秀次数与开秀次数有一定的正相关关系,但是也有模特曾经走秀18次却只开秀过一次的情况。
b.闭秀
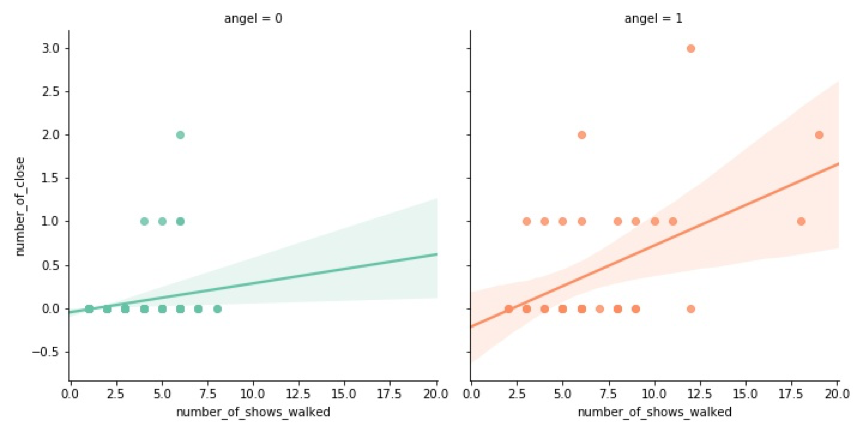
闭秀机会的获得对天使身份的要求似乎更宽松一些,我们发现了非天使模特闭秀2次的例子,但是这些参与过闭秀的非天使模特,无一例外地都有4-6次的走秀经历。她们分别是Ana Beatriz Barros,Carmen Kass,Magdalena Frackowiak,Naomi Campbell,Toni Garrn,其中Naomi也有过开秀经历,是非天使模特中很受维密重视的角色!
左半边橘色部分呈现出闭秀次数与走秀次数之间存在一定的正相关关系。
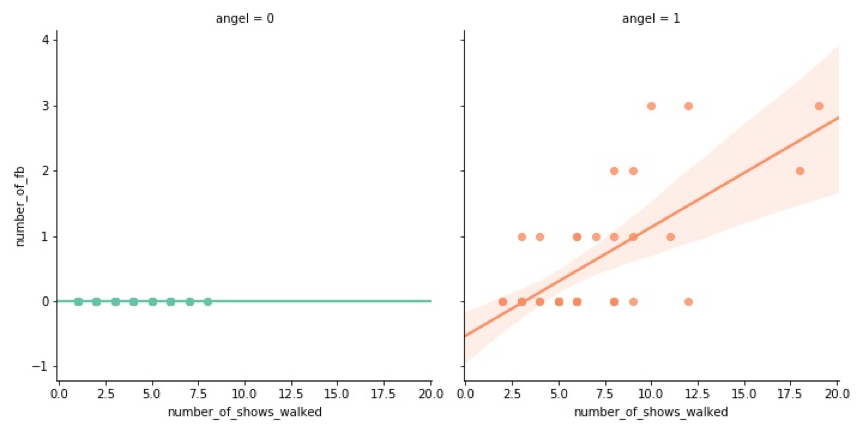
到了更为珍贵的fantasy bra这里,对天使身份的要求就非常严格了,所有的fantasy bra佩戴者都是维密天使,佩戴fb的次数与天使们走秀的年资也呈正相关关系。
Q7. 中国模特们在维密大秀是否也有了一席之地?
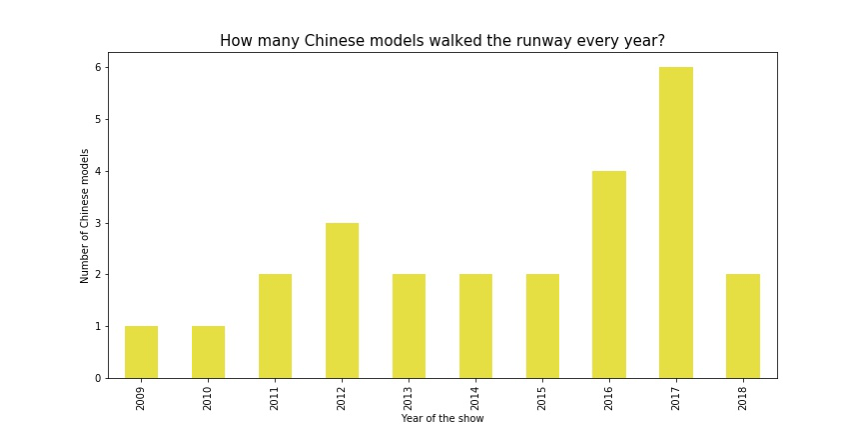
最后一个话题是我们都很关心的中国模特在维密T台上的发展态势,自从2009年有中国模特出现在维密T台上,历年参加维密大秀的国模数量总体是呈现上升趋势的。在2017年维密来到中国上海举办大秀时,国模数量达到了顶峰,体现出了维密对主办地市场足够的重视度;不过在今年即将举办的大秀上,国模的数量又回到了2名(分别是何穗、奚梦瑶,法籍华裔模特陈瑜未计入内),雎晓雯、谢欣、贺聪等模特的落选是让我觉得特别遗憾的。
Q8. 维密选人是不是越来越“花心”了?
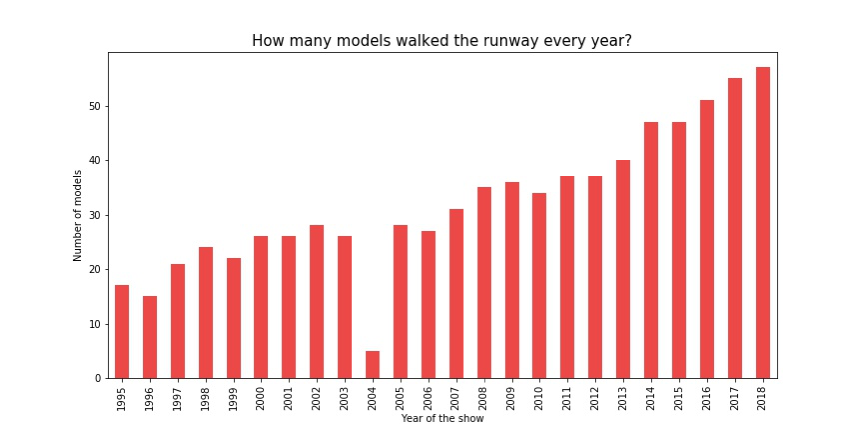
放眼望去,每年维密大秀启用的模特总数量都在逐年上升(04年的断崖是因为当年维密没有举办大秀)。那么维密每年启用的新人比例是否也同样在上升呢?带着这个问题我们构造了一个新的变量new_model来记录某年的某位模特是否是首次上秀,代码如下:
year = list(range(1995, 2019))
#将每年走秀的所有模特名字放在一个set中,从1995年到2018年一共24个set
model_list_by_year = list(range(0,24))
for i in range(0,24):
model_list_by_year[i] = set(df_show['model_name'][df_show['Event_year']==i+1995])
#令每一年的模特名字和前一年的取并集
model_list_by_year_accumulative = list(range(0,24))
model_list_by_year_accumulative[0] = model_list_by_year[0]
for i in range (1,24):
model_list_by_year_accumulative[i] = list(model_list_by_year[i].union(model_list_by_year[i-1]))
#将年份和每年的accumulative模特名单放在一起,组成一个dataframe
model_set = pd.DataFrame({'year': year, 'model_set': model_list_by_year_accumulative})
model_set.head()
#以1996年为例,先提取出某一年的走秀记录,到model_set中对年份进行匹配,再查找模特名字
model_1996 = df_show.loc[df_show['Event_year']==model_set['year'][1]].apply(lambda x: x['model_name'] not in model_set['model_set'][0], axis = 1)
#写一个for循环,对每一年分别进行查询操作,list中每一年都对应一个boolean series,一共有23年,得到一个由23个series组成的list
new_model=list()
for i in range(0,23):
new_model.append(df_show.loc[df_show['Event_year']==model_set['year'][1+i]].apply(lambda x: x['model_name'] not in model_set['model_set'][i], axis = 1))
#将23个series合并成一整个series, 再转成datarame
new_model_list = new_model[0]
for i in range(1,23):
new_model_list = pd.concat([new_model_list,new_model[i]],axis=0)
new_model_list = new_model_list.to_frame()
new_model_list.columns=['new_model']
#取df_show从1996年开始的数据,研究启用新模特比例的问题
df_show_new = df_show.loc[df_show['Event_year']!=1995,:]
#和new_model变量合并
df_show_new = pd.concat([df_show_new, new_model_list],axis=1)
#计算每年新上秀的模特比例,画图
plt.figure(figsize=[12,6])
plt.xlabel('Year of the show')
plt.ylabel('Ratio of New Models')
(df_show_new.loc[df_show_new['new_model']==True,:].groupby('Event_year')['model_name'].count()/df_show_new.groupby('Event_year')['model_name'].count()).plot.bar(color= '#f08080')
plt.title('How many new models were chosen every year?', fontsize=15)

虽然每年上秀的模特数量都在增加,每年上秀的新人比例却是在一直波动。2004年维密举办了Angels Across America Tour 来替代大秀,由五名老牌天使担任模特,所以我们在04年看到了一个触底的值。2006年之后除2009年的每一年,新人比例看起来都要比2002年以前的比例要低一些,选人的策略相比历史更为保守和固定了。
不过今年的新人比例与2017年相比,也是有一点提升,而且由于今年的模特基数是历年最高,崭新的面孔也就特别多了。在今年将要上秀的50余名模特中,首次上秀的模特有接近20名。一想到有这么多的新晋美好肉体将要出现在今年的大秀上,我就特别激动!吓得我赶紧放下手里的肥宅快乐水去减肥啦……
注:本文写于2018年10月9日,文中相关数据截至2018年10月9日。内容仅为作者观点,不代表DT数据侠立场。文中图片部分来自作者。
本文数据侠Haoyue Zhang,研究生毕业于杜克大学量化管理专业,想要进一步巩固数据分析技能而加入数据侠Python训练营。一枚热爱娱乐、文化、时尚行业的沙雕少女兼归国务工数据民工~

DT财经与纽约数据科学学院是战略合作伙伴。DT×NYCDSA 系合作开设的系列专栏。

数据侠计划是由第一财经旗下DT财经发起的数据社群,包含数据侠专栏、数据侠实验室系列活动和数据侠联盟,旨在聚集大数据领域精英,共同挖掘数据价值。申请入群请添加微信公号dtcaijing003并备注“数据社群”,合作请联系datahero@dtcj.com。

分享这篇文章到
2018-12-29

2019-01-04

2018-12-28

2018-12-21