
人工智能如何助力企业突围互联网运营困局?
2019-02-15

意见
反馈

回到
顶部

数据侠池志炜 2018-11-07
大家好,我是Shadow,一名有十年工作经验的技术宅兼设计师,目前是Get知识引擎的联合创始人,也是MIXLAB无界社区的创始人。我毕业后从事了很久的设计工作,设计师的经验跨越了甲方与乙方;同时也在做程序员,每天在设计师和程序员两种身份间不断转化。今天我将结合自己从事过的不同工作,来谈谈设计师与艺术家会不会被AI取代。
开始前,请大家猜一猜,以下哪张图片不是人类所创作?我们将在文末为大家揭晓答案。

设计师与艺术家会不会被AI取代?这个问题我在业界采访了很多人。做技术的人认为,AI是没有办法做一些创造性的工作的;但懂技术的设计师或艺术家,他们认为AI具备创作艺术与设计的潜力。
一直以来,我们认为设计师跟艺术家之所以无法被机器取代,是因为他们具备想象力跟理解力。
从想象力角度来思考,首先,机器不具有真正意义上的创造力,因为机器没有想象力。创造力,其实是人类独有的东西。美国生物学家爱德华·威尔逊在《创造的起源》中提出,创造源自人类的冲动。人的思维是发散的,不能够用数学公式描述,人类设计师在从事设计工作时会偏离正轨,正是因为这种冲动,才有了创造的可能。
但机器不会犯错,它只会处理1+1=2这种结果很明确的问题。即使我们引入一些概率到AI的系统里,假设程序运行正常,那么机器也不会太偏离正轨。
所以,从冲动这个角度看,机器不具备真正意义的创造力。
从理解力角度思考,我们认为机器不具备理解力,但是理解力可以被假装。
约翰·希尔勒提出过一个著名的思想实验 Chinese Room。整个实验的场景如下:
“一个对中文一窍不通的,以英语为母语的人被关在一个只有两个通口的封闭房间中。房间里有一本用英文写成的从形式上说明中文文字句法和文法组合规则的手册,以及一大堆中文符号。房外的中国人不断向房内递进用中文写成的问题;房内的外国人按照手册的说明,将中文符号组合成答案,并将答案递出房间。”
在这个实验中,约翰·希尔勒认为,尽管房内的外国人可以以假乱真,让房外的中国人以为他是中文的母语用户,但事实是他压根不懂中文。把这个情景放到机器操作中,可以这样理解,程序员相当于实验中房外的中国人,计算机相当于房内的外国人,而代码则相当于手册。正如房中的外国人本身并不具备对中文的理解能力,他必须通过手册才能理解中文;同理,计算机也不可能通过代码来获得理解力。但就像房外的中国人会误以为房内的外国人懂中文,我们其实也可以认为计算机具有理解能力,因为它可以读懂代码。
基于这个实验,我们认为理解力是可以被假装的。
所以,如何让机器学会“创造”?前提是让机器理解我们的艺术。既然理解能力是可以被假装的,当我们再回到创造力这个方面思考时,会发现其实没有必要让机器具有哲学意义上的创造力,只需要假装具有创造能力就好。
如果我们将对创造力的定义稍微放宽,将其定义为推陈出新,从技术的角度看,只要数据做得足够好,那么推陈出新的这种创造是完全可以做到的。
综合前面两个观点,以及我们对创造力的重新定义,我们认为机器创造以及机器的艺术行为是可行的。
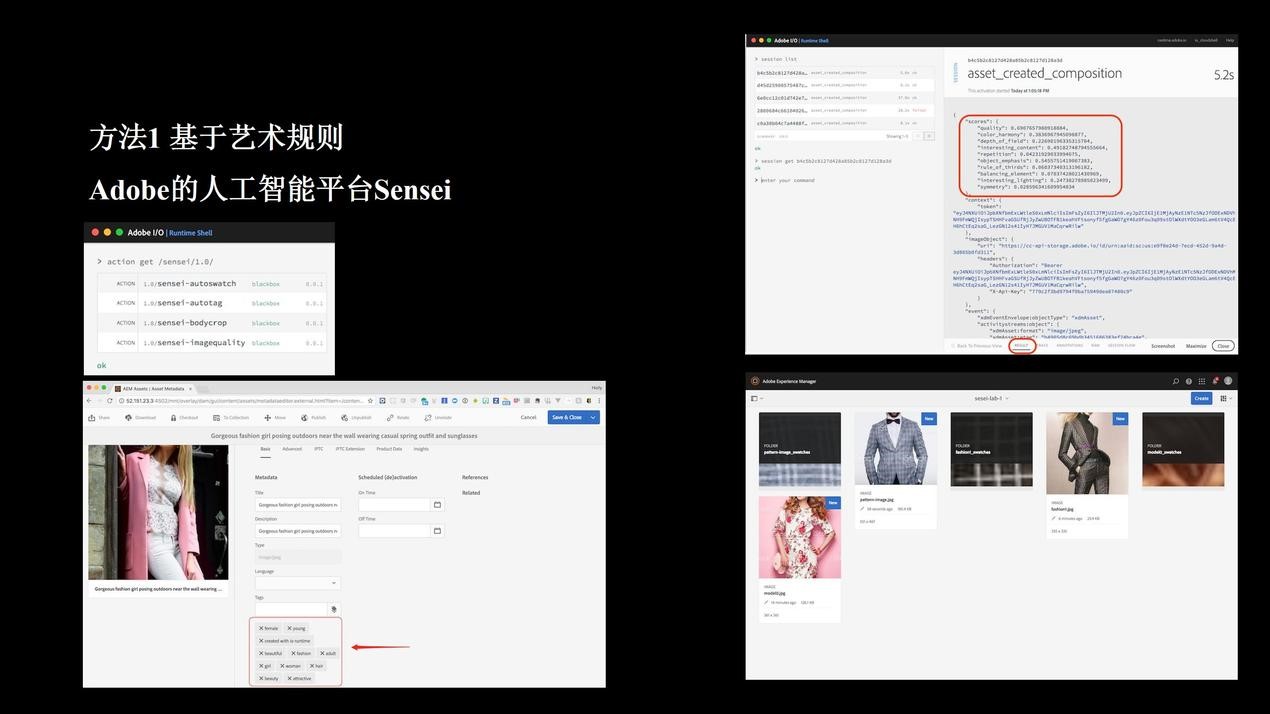
在日常的艺术创作中,总会有一些艺术规则可循。结合Adobe最近公布的人工智能工具Sensei的案例来看,这个工具有一个图像质量评估的能力,它给出了评估图片质量的十个纬度,这其实就是一些所谓的艺术规则。将这些艺术规则通过机器语言表达出来,机器就具备了理解艺术作品的能力。

除了评估图片质量,这个AI工具还具备了图片主体的裁切(自动扣图)、自动提取颜色的色板、给图片打标签等功能。
通过数据,我们可以挖掘到平常无法直接得到的潜在规律,从而解读一些艺术或设计作品。在艺术领域涉及最多的媒介是图像,通过对图像的分析,我们能够得出一些量化方法。

今天我们分享一个关于图像色彩风格的量化方法。图像色彩风格的量化,简单来说就是将图片颜色进行压缩,得出颜色种类、比例以及空间关系等量化指标。MCCQ或者Kmeans这类算法都可以用于色彩量化。
如何进行图像色彩风格的量化?
第一步需要量化图片,压缩颜色。以下图为例,通过算法,可以获取图片三个典型的色彩数据,再基于这个色彩数据来压缩整个图片的颜色,获得压缩色彩后的图片以及图片的一个色板。

在获取了图片的主要颜色、并且把这个颜色量化之后,第二步是需要获取各个颜色之间的关系。下图是我们获取的关系,节点跟节点之间通过连线,表达了颜色之间的空间关系;节点的大小,表达了这个颜色在这张图片里面所占的比例。

使用邻接矩阵的方法将图片进一步量化。通过矩阵来纪录所获取的三个主要颜色出现的频率,颜色每出现一次我们累计一次。
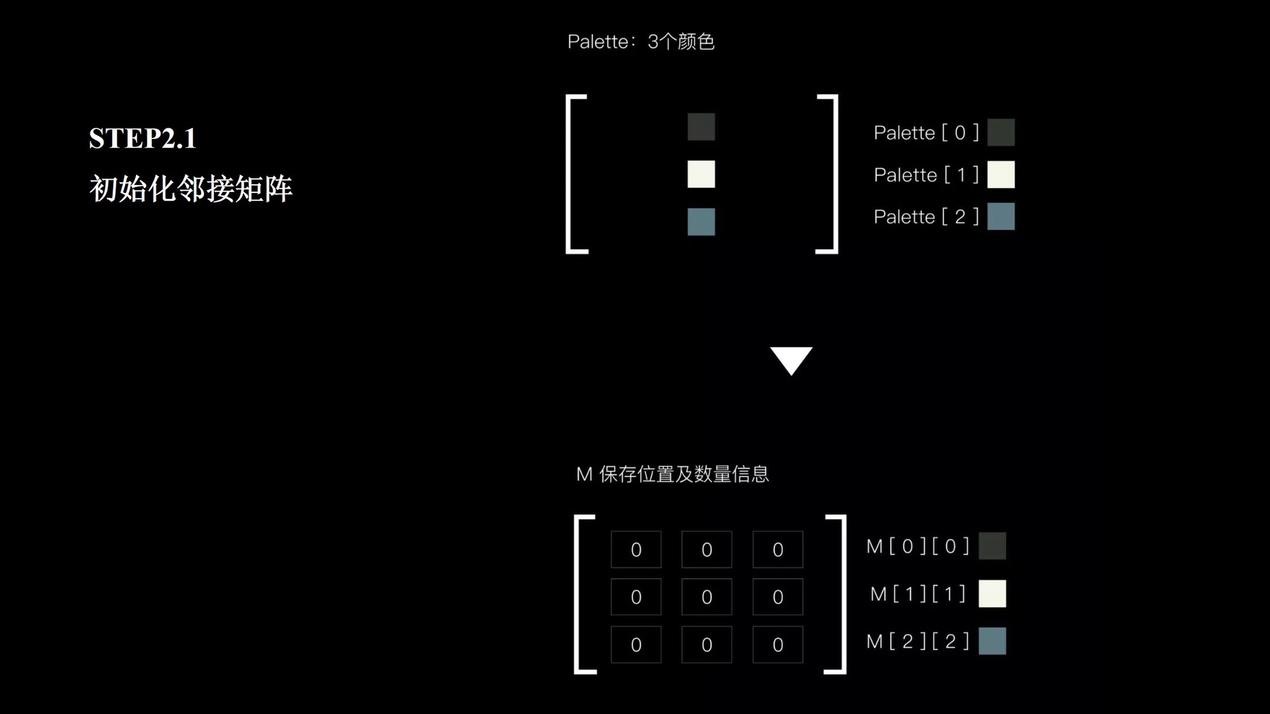
遍历量化后得出相应颜色矩阵。P1、P2、P3、P4代表了3种主要颜色,其中P1、P2代表同一种颜色。当每一张颜色出现时,都会相对应的对他们这个邻接矩阵进行加1的操作。

简单来说,对图片色彩风格的量化就是一个遍历的过程。首先我们会获取四个像素点,然后获取四个像素点在色板中的位置,以此作为这个邻接矩阵的编号,如果任意两个像素之间的颜色不相等,那么这两个颜色之间的连接程度我们会加1,对应的邻接矩阵中元素的数值也会加1。

在得到运算过的邻接矩阵后,为了计算方便,我们会经过归一化处理,这样一张图片的色彩关系就能被很好地量化了。经过量化之后,我们其实已经让机器理解了色彩。
经过量化之后,我们如何用机器获取的数据做应用呢?
摄影是日常生活中最接近艺术的一种行为。网络上存在大量优美的人物摄影作品,我们如何让机器提炼出最佳的人物摄影姿势,从而指导人们拍摄出一个不错的人物摄影作品?

利用深度学习的人体关键点识别技术,对海量摄影作品图片的人物姿态关键点以及画面的构图关系进行数据提取,最终通过这些数据的聚类,获取一些典型的类别,从而在大量的摄影作品中,发现最好的人物摄影姿势是什么样子。
数据提取与处理后,可以通过创造一个知识图谱,构建各种好玩的、关于摄影的应用程序。
比如研发一个叫人工智能摄影师的产品。“摄影师”会自动跟拍用户,基于已经构建的知识图谱,对大量跟拍的摄影照片进行排序,自动为用户挑选出一个最佳的摄影作品。
如何用机器理解整个图片的色彩关系?除了在上文中提到的色彩邻接矩阵之外,我们还可以通过计算颜色之间出现的频率,并且把这个频率转化成向量的表示方式,构建一个彩色知识图谱,实现在搭配、绘画、电影电视剧的色彩风格及氛围的营造等关于颜色的场景中的应用。

基于word2vec的颜色图谱构建,最典型的是在设计图或者绘画上的应用。当用户上传一个设计图,机器会自动修改颜色的搭配,并生成很多种配色方案,设计师只要专注于画手绘图,剩下的配色工作机器都能完成。
还有一个典型是应用于服装作品。我们可以通过提取海量服装作品的颜色,了解每一个作品的颜色搭配情况、设计师在这一季度发布的服装的整体配色喜好,并推断出整个系列的设计风格。再放大一些,可以通过采集大量设计师的服饰设计图片,计算出这个时间段服饰搭配的整体趋势,运用在新款的发布中。
不仅如此,我们还可以分析模特肤色与服装色彩搭配之间的关系。有了这两类数据后,我们可以设计这样一款应用:用户上传自己的照片后,应用会自动计算和识别出肤色,并根据肤色自动搭配一个服装。除了服饰之外,配饰、妆容(例如口红色号)也可以实现个性化推荐。
除了服装,我们生活中关于颜色的应用场景还有很多,比如室内装修。当大家挑选墙面漆、墙纸的时候,如果机器已经掌握了大量配色方案,就可以很好地为我们计算出最优选。
小伙伴们还记得一开始的六张图吗?究竟哪一张图片是AI创作的呢,请在DT数据侠(DTdatahero)后台回复“机器设计”,看看你的答案是否正确~

本文数据侠池志炜,10年跨界设计&开发经验,擅长智能产品架构、智能设计。毕业于上交大/同济大学硕士。曾在中兴通讯任高级软件开发工程师,招商银行任资深用户体验设计师,ARKIE智能设计任高级产品经理/机器学习研究员,某区块链通用智能硬件平台产品顾问,现为GET知识引擎联合创始人、AI产品架构师。独立APP作品:spyfari、采色灵感、aceland。微信小程序作品:预测Mix。同时是自媒体mixlab的作者,mixlab无界社区创始人,目前已形成 1500人+ 的设计师&程序员跨界社群。知乎专栏《人工智能+区块链+设计修炼指南》作者。
“数据侠计划”是由第一财经旗下DT财经发起的数据社群,包含数据侠专栏、数据侠实验室系列活动和数据侠联盟,旨在聚集大数据领域精英,共同挖掘数据价值。了解数据侠计划详情请回复“数据侠计划”,投稿、合作请联系datahero@dtcj.com。

分享这篇文章到
2019-02-15

2019-01-17

2019-01-08

2018-12-24