
人工智能如何助力企业突围互联网运营困局?
2019-02-15

意见
反馈

回到
顶部

Emanuel Kamali 2018-10-26

随着科技发展不断推动各行业的信息化进程,纽约标志性的出租车小黄车们却拖了后腿。在Uber、Lyft等共享出行平台的竞争下,小黄车也开始和Google合作,让自己的服务变得更加以数据为中心。小黄车希望Google可以通过它们提供的数据,设计出一些新的功能从而进行出租车价格的预测。这些数据信息包括:
纽约市出租车小黄车、Google和美国大数据竞赛平台Kaggle合作,设置了一个数据应用竞赛,让想要“把玩”这些数据的玩家们可以尝试通过这些数据集来设计一个机器学习算法,用以预测车费。我们的目标就是,通过分析这些数据集,设计出一些新的功能,让新的数据可以在我们的算法和代码中运转,并最终得出预测车价。
为了设计一个有效的机器学习模型,我们需要先做一些事情来保证模型是精确的。首先就需要对小黄车有更多的了解,所以我先做了一些研究,弄明白它的计费模式。
于是我进一步探索数据,研究不同的时间点打车是否影响价格。在对数据进行处理前,我先研究了一下打车价格数据的分布情况。
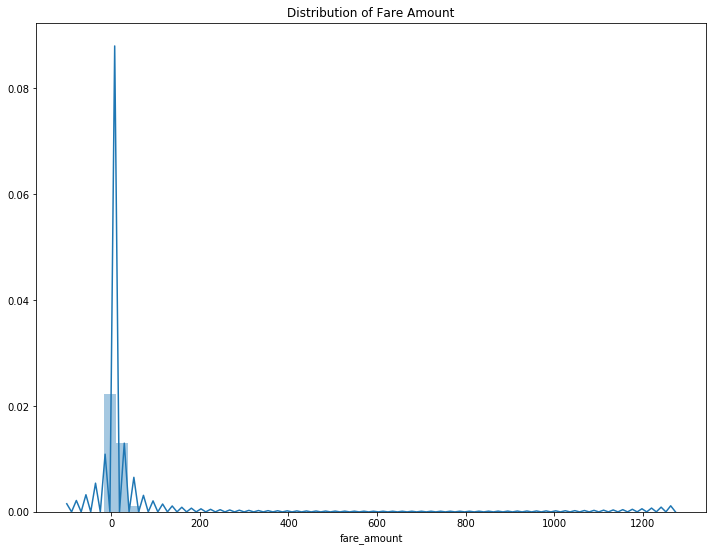
可以看到,这组数据是十分分散的,也就是说我们的数据集里有很多异常值。我把这些异常值去除,可以更直观地看到价格的分布情况。
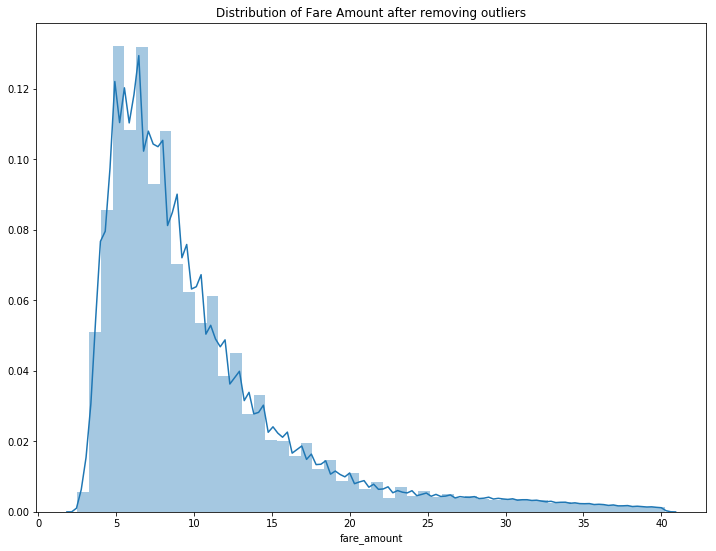
上图显示,这组数据里的价格区间在2.5美元到40美元之间。
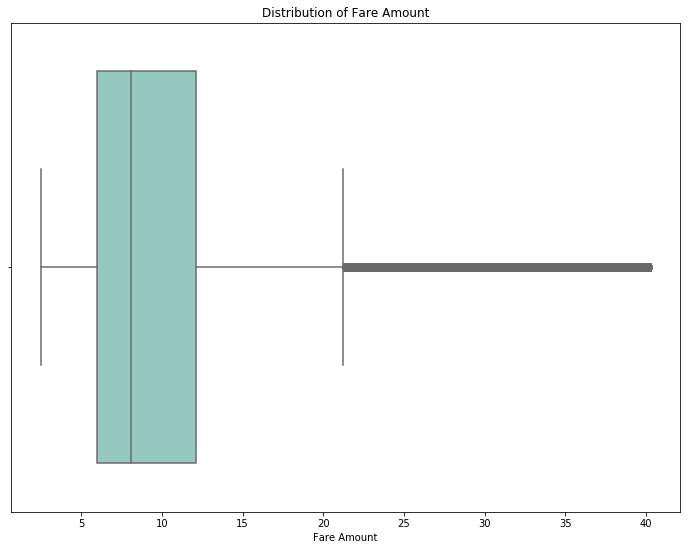
在对上下车地点的数据进行清理后,我们仔细研究一下不同时间对价格的影响。
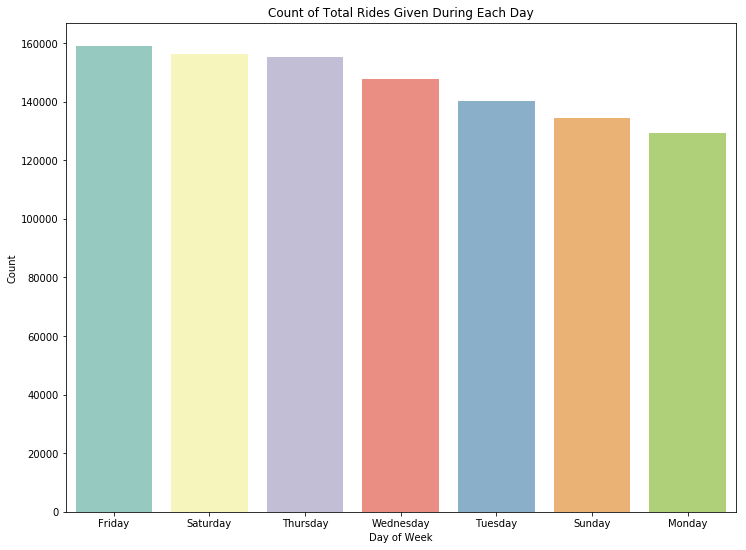
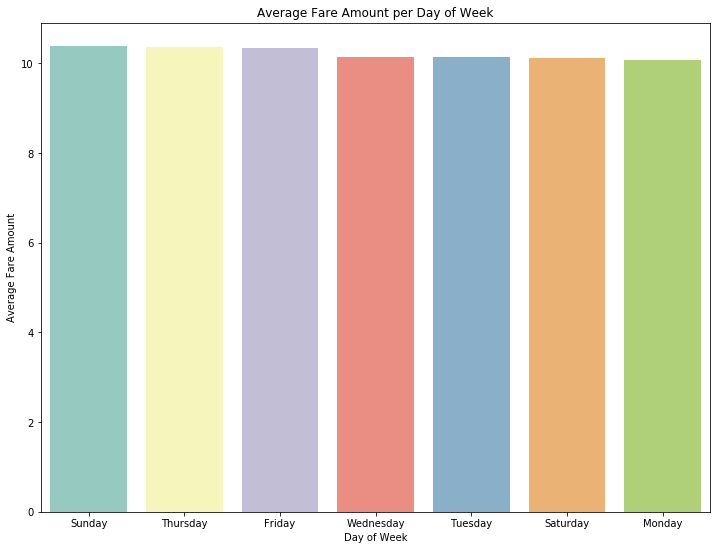
从上图可以看出,周五周六和周四的乘车次数最多。这可以理解,因为在美国人们周末通常会更多的使用出租车。如下图,当我们研究某一个给定日期内不同时间点的平均价格时,会发现并没有太大的区别。
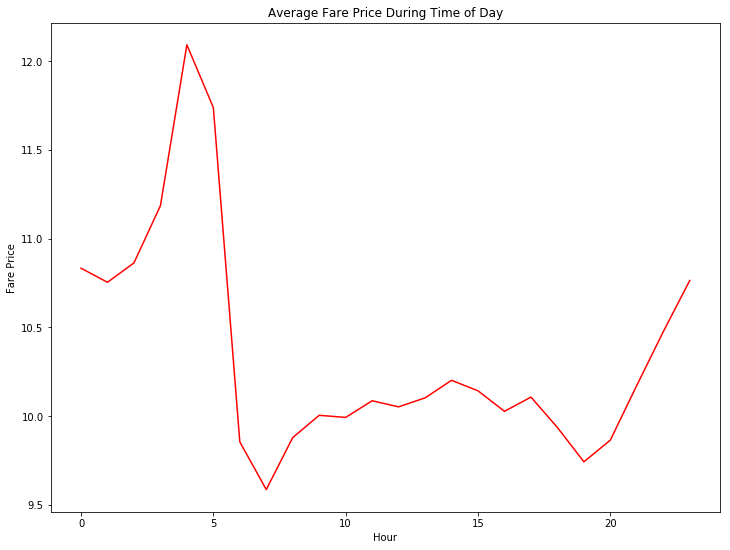
下图是一天24小时的平均价格分布。横轴代表了24小时。
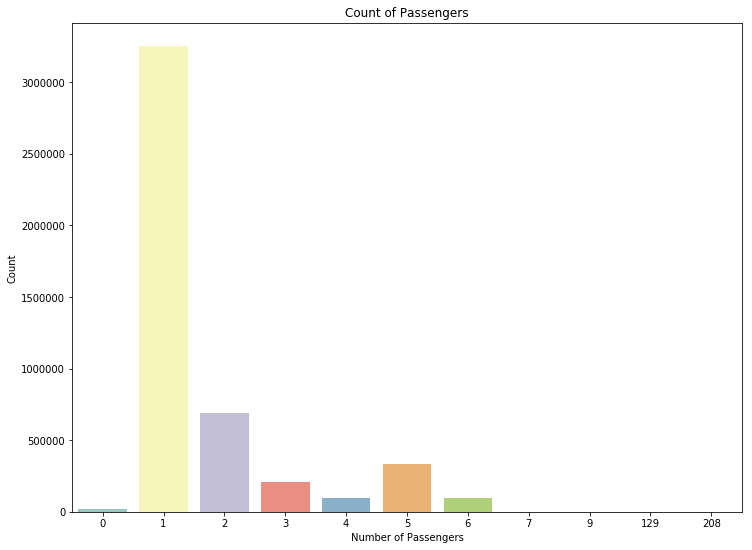
接下来,我的研究了一下打车人数数据,发现有些蹊跷的地方。一辆小黄车可以最多搭载7名乘客,但是在数据中我们只找到非常少的7人满载搭车的情况。另外,还有一些数据显示搭载人数为0,这也不合常理。于是这些数据可以被筛选清理掉。
去除掉0名乘客和大于6名乘客的数据后,我们得到一个更加真实的图像。
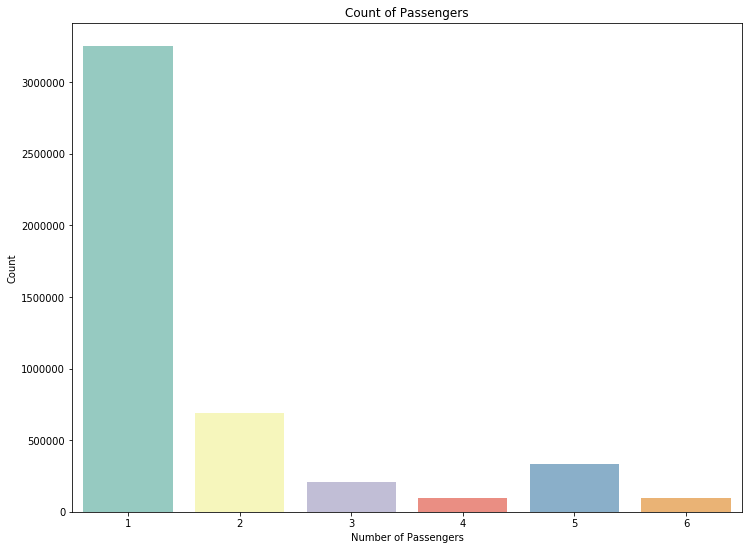
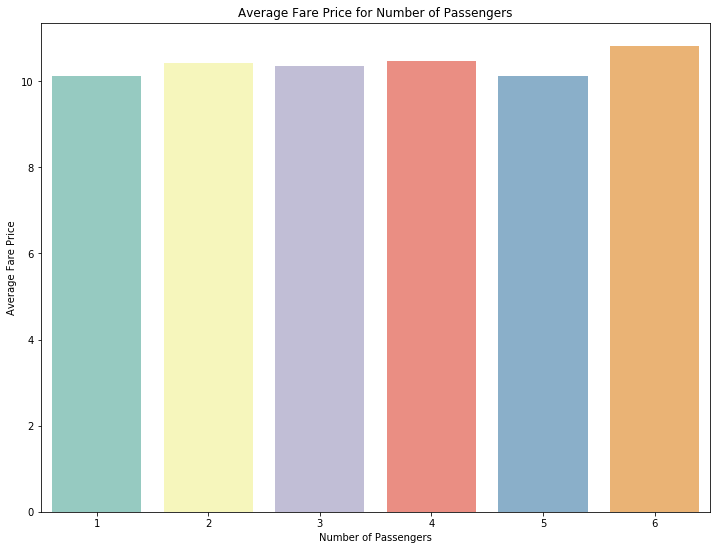
从下图可以看到,乘车人数和对应的价格的区别并不是很大。
研究完了小黄车一天不同时间的不同价格,我开始研究为什么这几年打车价格不断上升。我把指标改为年-月的计量单位。这样我可以看到不同年份的价格变化。
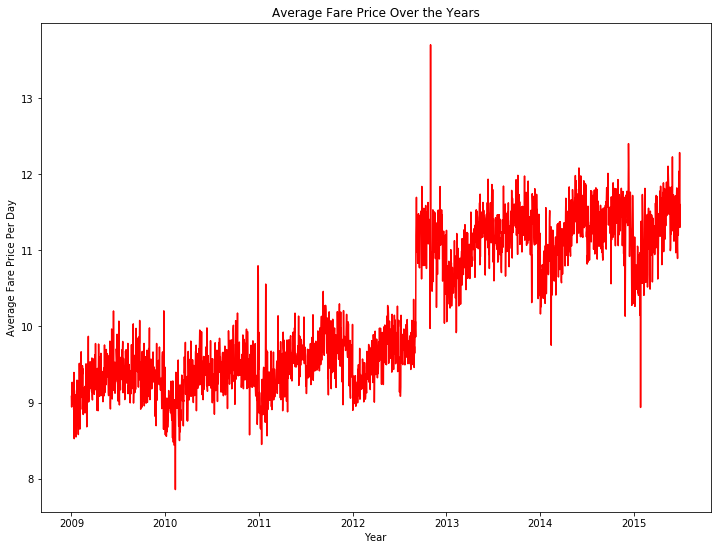
从上图可以看到,2012-13年期间价格有一个高点。下图是每个月的价格情况。
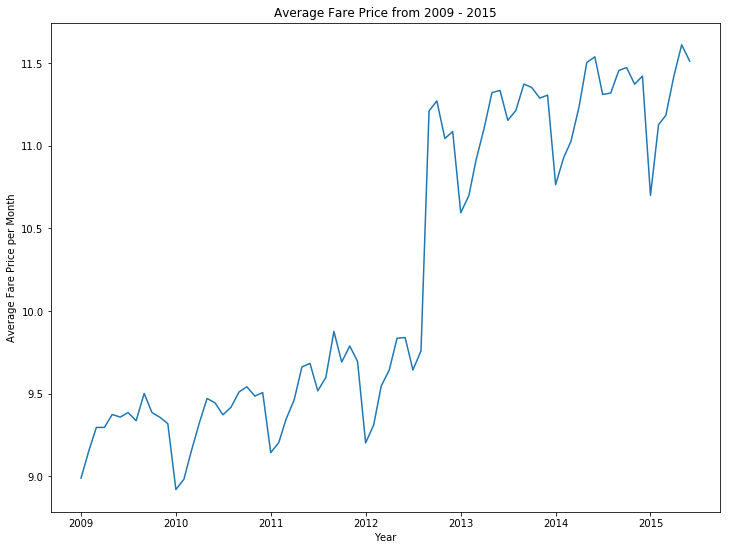
从中也可以看到2012-13年的价格飙涨。作为一个数据科学家,这是我想要进一步挖掘的发现。我在网上搜索后发现,2012年9月3日一篇纽约时报文章对当时纽约车费的上涨做过报道。
本次的车费预测研究简单总结如下:
在我清理了数据、将上下车地点数据换算成里程公里数后,我开始将数据输入到我的机器学习模型中。我使用了三种模型:多重线性回归,随机森林实现以及GBR(gradient boosting regression)。
我使用均方根误差(RMSE, root mean square error)来判断哪个模型表现最佳。在展示结果前,我们先看一看随机森林和GBR的模型的不同。
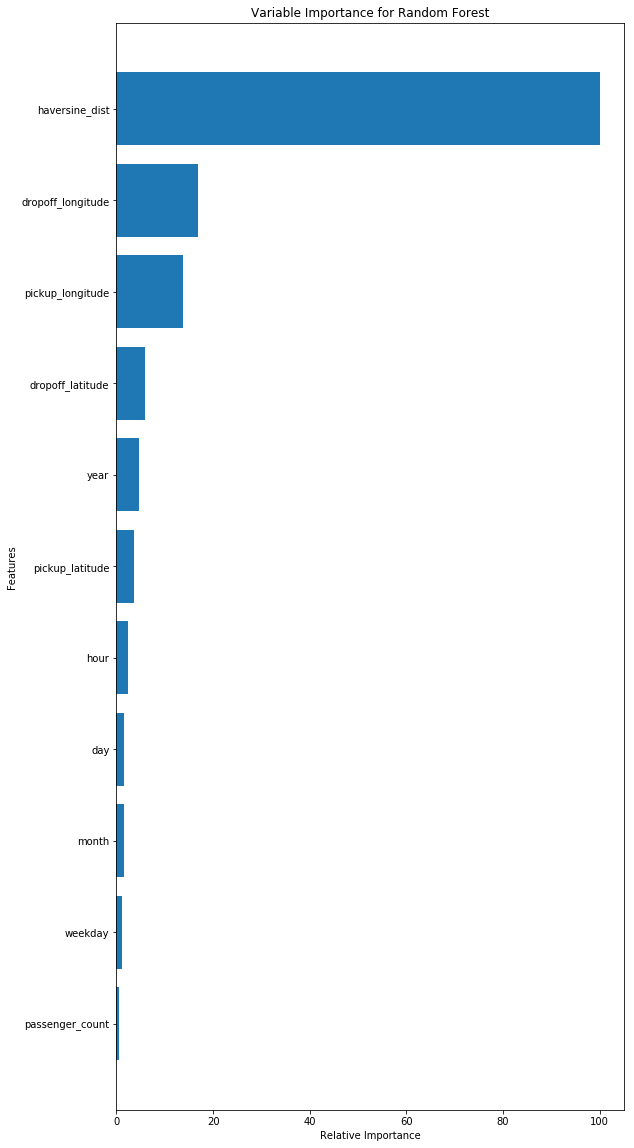
对于随机森林,最关键的影响因子是Haversine-dist,也就是上下车地点间的距离。其他的因素影响很小。
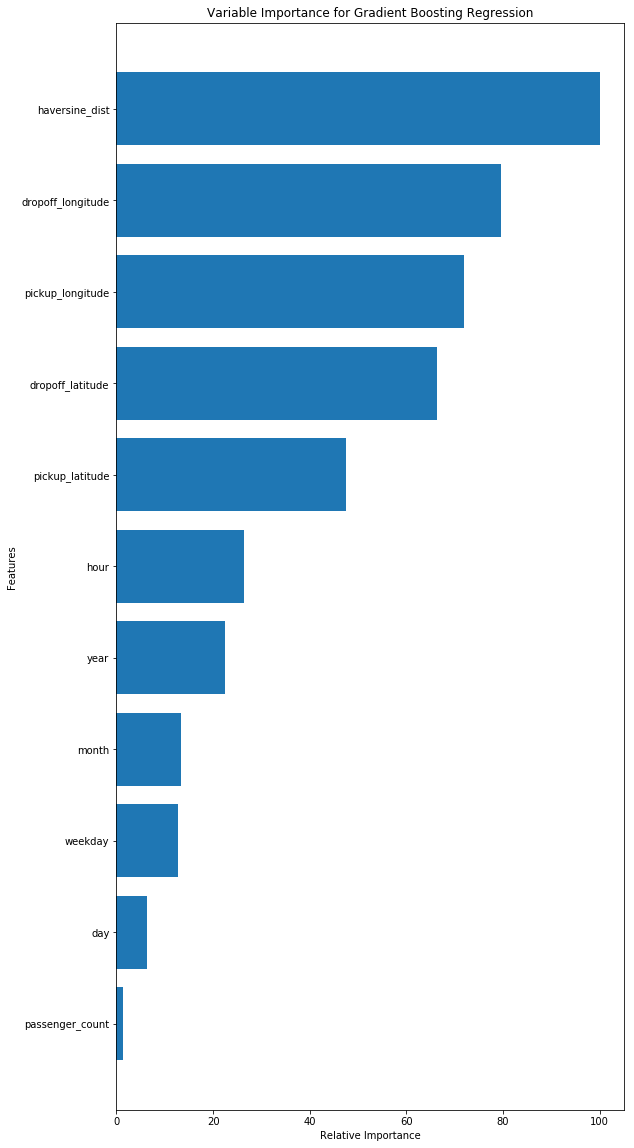
而对于GBR而言,Haversine-dist也是很重要,但是其他的包括上车地点、下车地点也很重要。
对于这两个模型,乘客数看起来都不怎么重要。
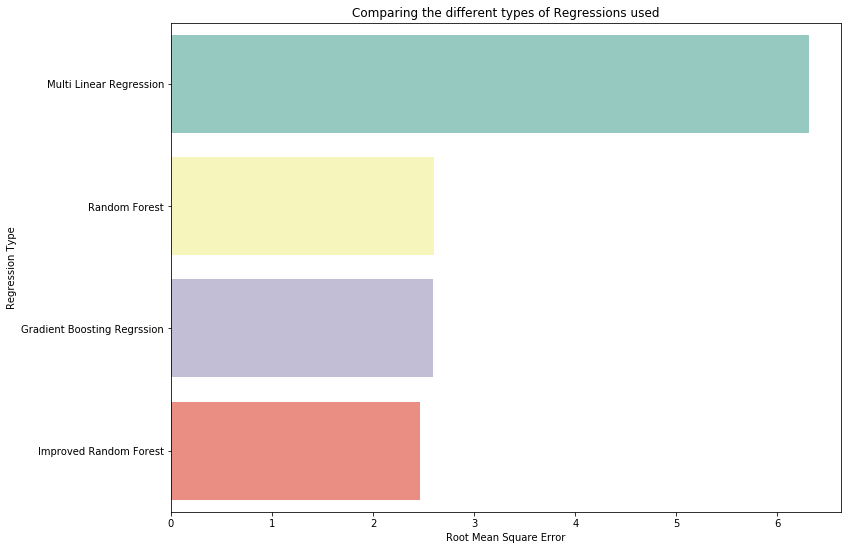
从最终结果看,随机森林模型表现最好。它的均方根误差为2.418左右,这意味着当我们的模型算出一个预测值时,最终真实的价格可能只相差2.418美元。
今后还可以做更多的尝试,来提高准确度。比如,如果我们可以把去机场的车和其他地点的车分隔开,就可以进一步研究在纽约市打车的人们都去了哪里。
如果你需要查阅本文可视化代码和机器学习模型,请前往作者Kamali的GitHub。
(以上内容编译自纽约数据科学院博客Predicting NYC Yellow Cab Taxi Fare,仅代表作者观点)
Emanuel Kamali,纽约州立大学宾汉姆顿大学艺术与应用数学专业毕业,除了喜欢研究机器学习外,还对讲述故事以及数据科学的创造性一面非常感兴趣。

DT财经与纽约数据科学学院是战略合作伙伴。DT×NYCDSA 系合作开设的系列专栏。

数据侠计划是由第一财经旗下DT财经发起的数据社群,包含数据侠专栏、数据侠实验室系列活动和数据侠联盟,旨在聚集大数据领域精英,共同挖掘数据价值。申请入群请添加微信公号dtcaijing003并备注“数据社群”,合作请联系datahero@dtcj.com。

分享这篇文章到
2019-02-15

2019-01-17

2018-12-29

2019-01-03