
这星球上最有钱的人们是什么样的?让我们用大数据一窥究竟
2019-01-04

意见
反馈

回到
顶部

Mitchell Hung 2018-03-26
近几年reddit越来越火,2014年它的页面浏览数超过700亿。根据Alexa的数据,2017年,reddit是美国浏览量第四,全球浏览量第七的网站。超过4%的美国成年人使用reddit,其中67%是男性用户,他们大多数年龄较轻,在18到35岁之间。
当我们研究reddit,其实是在研究全世界最大的网民群体之一。更重要的是,reddit上占统治地位的用户群体也是互联网最具价值的目标群体:18岁到35岁之间的男性。对于所有未来的广告主,reddit是一个名副其实的信息金矿,了解其用户和内容的特征是势在必行的任务。
所以,我主要我带着两个较为宽泛的问题展开研究:
我们可以从reddit的用户行为以及网站结构观察到哪些行为范式?
从市场营销的角度,在reddit上做广告的最佳方式是什么?
我最初的直觉认为,想知道reddit上最成功的营销活动什么样,首先就要看看那些已经证明成功的营销策划中使用了什么内容。因此,用户行为的分析很关键:什么样的特质让优质帖子从其他帖子中脱颖而出?我们能否找到一些因素或是策略,从而让提交的内容效果最大化?
当然这并不是说reddit是一个可以简单定义的单一的社区。Reddit其实很多样化,它拥有大量的子板块,被称为“subreddits”,这些子板块都有不同的文化、标准和用户画像。我并没有计划对每一个子板块单独制定策略,我的目标是对由多个子板块构成的较大的社区进行定义,如果我的尝试成功,那么我们就找到了适合营销的较大规模的标的群体,可以用在一些更宽泛的广告策略中。
由于我只有一周时间收集数据,我放弃了设计一个能主动收集数据的网络爬虫的方案,而选择了对静态的历史数据进行爬虫。在有限时间内,后者明显可以收集更多数据。接下来我爬取了150个最受欢迎的子板块中的最佳帖子。
值得注意的一个限制是,reddit仅显示每个子板块中的1000个最棒的帖子,因此之后的分析都会受限于这些帖子本身的特征。然而,因为我的项目本来就只想分析最成功的帖子,这反而成了一个我期待的、在数据选择方面的人为干预结果。
最初我想用Python的Scrapy进行爬虫,但很快发现由于reddit使用了动态HTTP地址,这方法不行。我采取的方法本质上是模拟人的操作,好像有人在手动点击下一页一样,借此避开reddit的反爬虫设置。
因此Python的Selenium最适合我的任务:Selenium会模拟包括鼠标移动和点击的所有动作,这正是我所需要的,虽然它的这一特性让它在节约时间上比Scrapy等直接发送请求的爬虫要逊色,但在我这里这却成了优势。对于数量级更大的数据爬取任务,selenium肯定不适合,但对于我的任务(大约仅有130000个观察对象),它已经足够快了。
我爬虫的工作原理如下:我将一个包括150个子板块的列表放入爬虫程序,对于每个子板块,爬虫会生成一个相关URL(这个URL对应的是子板块的历史最佳帖子),之后程序会前往这些URL进行相关操作,获得每个帖子的相关信息。这些信息都是符合一系列XPath语言的,其数据维度包括:子板块,题目,帖子对应的域名,提交帖子的用户名,获得点赞数。这些数据之后放置在各子板块单独对应的CSV文件中。在下面的 Github 链接中可以看到更多信息。
首先,出于我自己的好奇,我先看了看各个帖子获得的点赞数随时间变化情况。下图同时也显示了整个网站的增长情况:越近期的帖子对应着更高的点赞数,说明用户数在随时间增长。
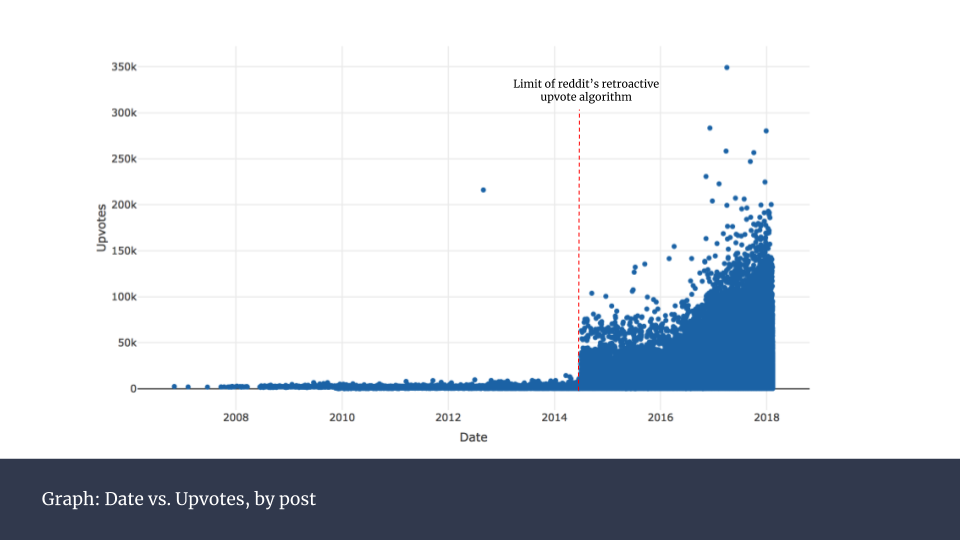
在图中可以看到一个明显的人为干预产生的“突变”。在图中所示2014年年中的地方,我做出了标记。2016年12月,reddit宣布采用一种改良的方法来计算点赞数。点赞数不再是简单的加总,而是经过一个黑箱算法处理过后的数据。这个算法的原理并未公开,因此只有最终显示出的这些数字可以用来分析。无论如何,reddit方面表示,这样做的目的是为了更好地反映真实的点赞情况。
在实践中我们可以看到,这样的变化的确大幅提升了点赞数。但从图中可以看出,这样的改变对过往数据的影响方面,仅仅在特定日期(2014年6月29日)出现巨大变动。为了保证之后分析的可信度,我尝试对没有受到点赞统计规则影响的数据进行修正,效果如下:

这样操作后,整个数据集的变化更加平滑。你可能会发现2012年出现过一个极端的点,我用红色标示出来。这并不是出错了,它是当年美国总统奥巴马参加的一个热门问答贴。
出于一探优秀用户行为习惯的好奇,我接下来对100个最有名用户的点赞数进行可视化。
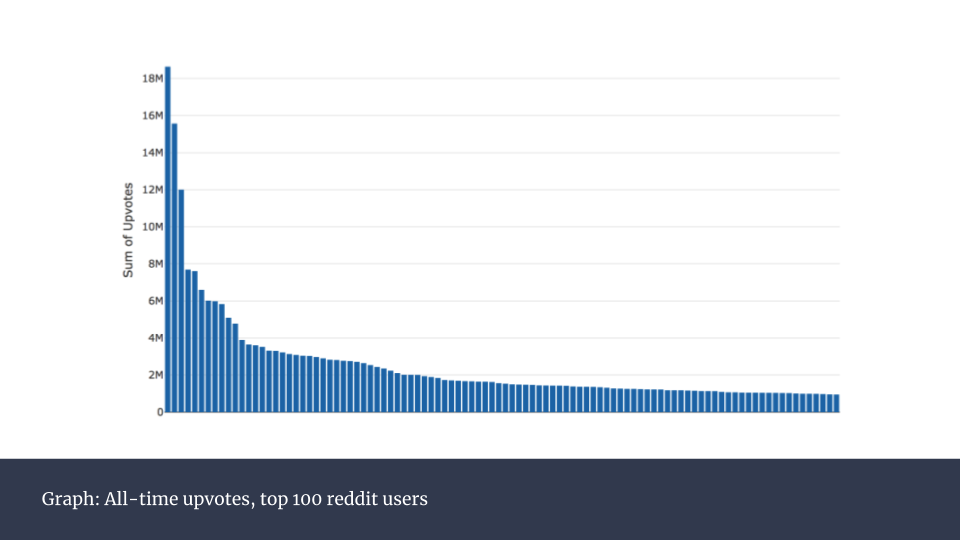
这是一个非常头重脚轻的分布。其实,前100名用户占了全部12%的点赞数。考虑到2017年reddit已经有超过16亿独立访客,这显得非常不平衡。而这也揭示出这些头部用户的发帖方式与其他普通用户肯定有很大不同。接下来我们就来研究这些成功的帖子背后有哪些特征。
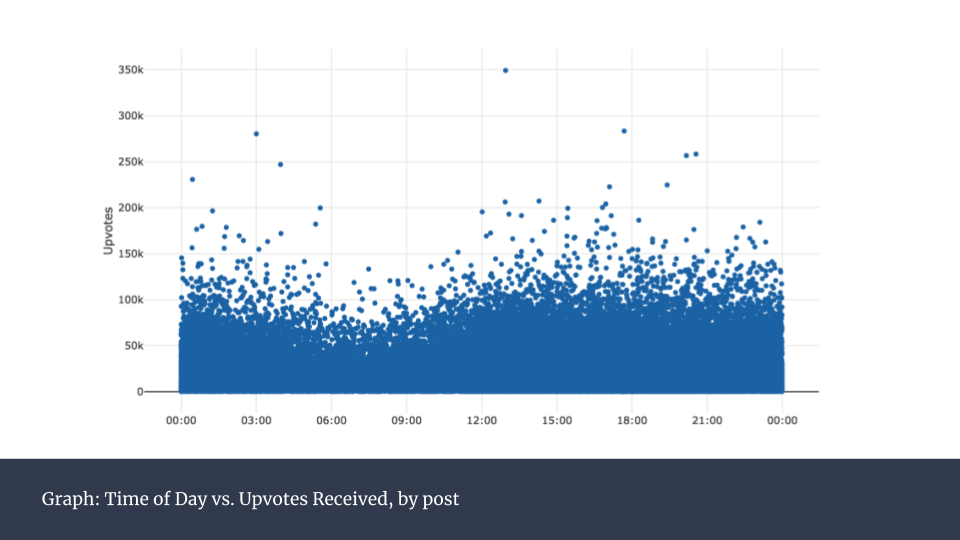
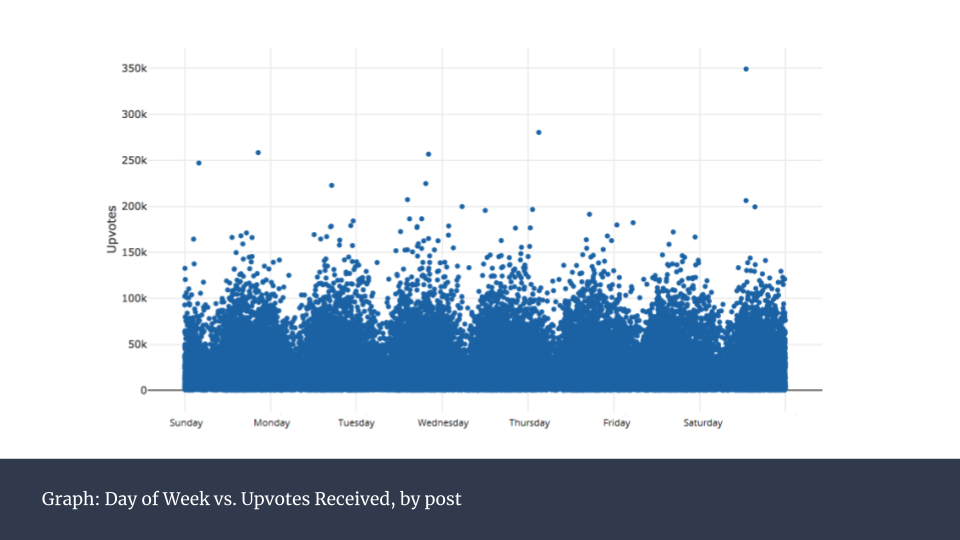
上图是所有帖子在一天内的发帖时间的分类统计,可以看到0点到12点之间呈下滑走势。而这之后,平均数保持平稳。按照星期来统计(下图),则没有发现任何规律。
接下来我对获得点赞最多的帖子中包含的链接所对应的域名进行分析,将每一个域名的全部点赞数加总呈现在下图。
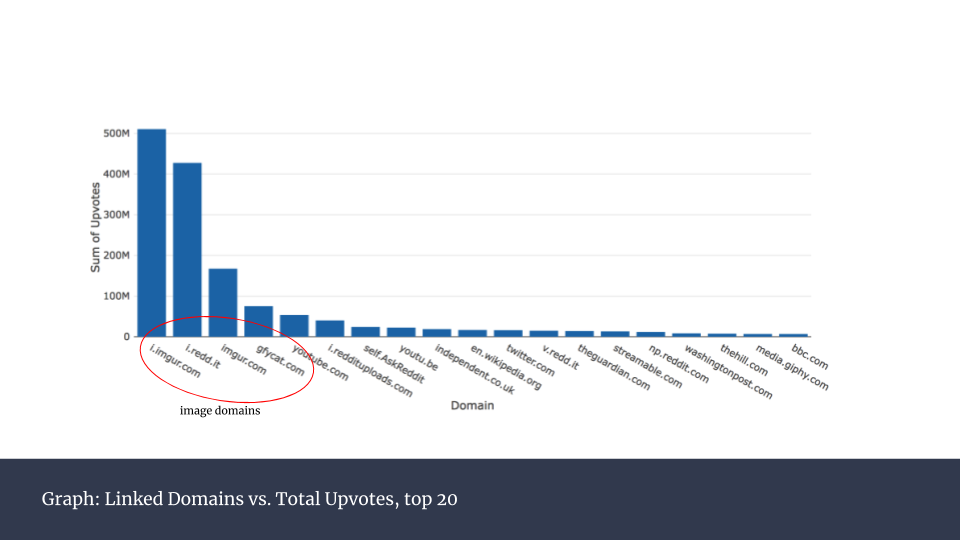
一个有趣的发现是,前四个域名都是图片网站。换句话说,最成功的帖子的内容几乎都是纯图片的。这并不意外,在网络上,图片是最容易被人快速识别的内容,各类网站都已呈现出这样的趋势。
最终,我将各个子板块的点赞数总和呈现在环形图中。需要注意的是,因为我每个子板块只爬取了1000个帖子,因此下图并不代表整个点赞数的趋势。子板块越受欢迎,它们的帖子数也会陡增,点赞总数也会比下图显示的多很多。
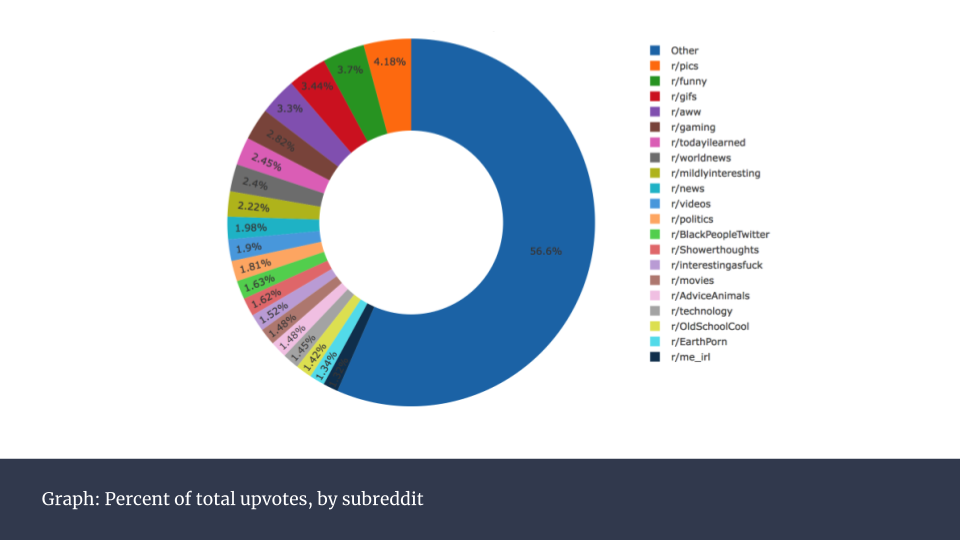
拥有最多点赞数的子板块基本就是最受欢迎的子板块,除了r/announcement。它是订阅数最多的子板块,然而只有reddit员工可以在这一板块发帖。
接下来我开始对reddit内的社群进行分析。我使用了Raghavan等人在《Near linear time algorithm to detect community structures in large-scale networks》中提到的算法,建立了一个网络相关性模型。模型中的顶(vertices)包括20个最热门子板块,边(edges)的值由子板块彼此之间的帖子数量来确定。最终得出下面这张热点图,它有点像一个皮尔森相关系数图表。

从中可以看到许多很强的相关性。比如r/movies(电影)和r/todayilearned(今日学习),以及r/movies(电影)和r/gaming(游戏)。
而下面这个网络图可以更直观的呈现这些相关性:
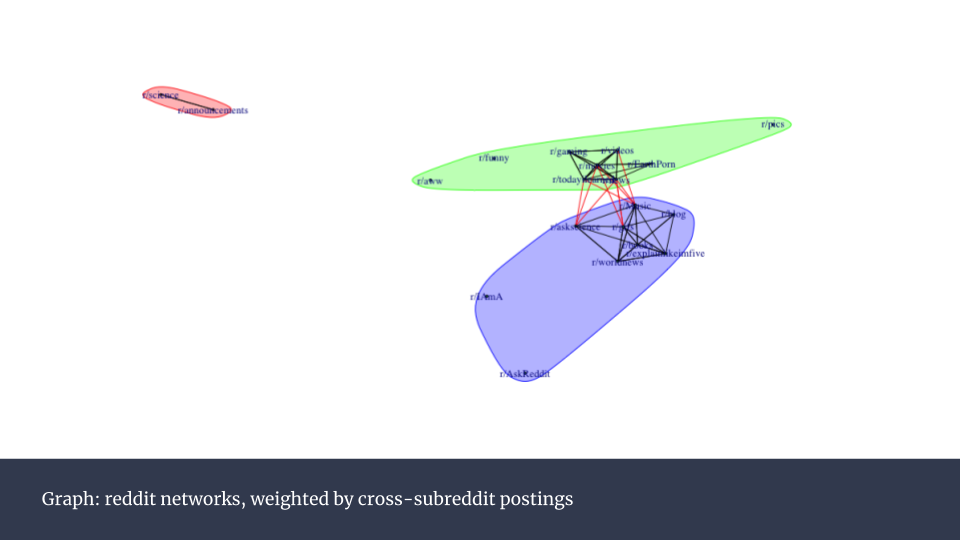
只有边的值超过平均值的被挑选出放在图中。红色线条对应的数值高,黑色对应的更低。不同颜色的组别可以看作一个社区。他们拥有类似的用户,这些用户会在这些区块包含的子板块之间发帖。当我们想要区分拥有相似行为习惯的用户构成的社区时,这种分析尤为有用。因为对于r/movies有用的市场策略也许就可能同样适用于r/todayilearned。
尽管这项目仅仅碰到了reddit这个数据富矿的一点皮毛,但依然收集到惊人数量的信息。
效果很棒的帖子拥有不少共同点。一个好帖子需要在合适的时间发布,需要包含正确的内容(比如一张图片),而且它应该属于一个特定的子板块。这些结论很多是符合直觉的,但得到数据的支撑依然很重要。
Reddit的用户可以被分成不同的特定社群,而且各自在用户习惯等方面拥有很高的确定性。我的项目仅涉及了20个单独的子板块,但未来的项目可以覆盖更广,而且还可以将评论也纳入分析中,到时候一定会发现更多相关性。
(本文编译自博客 Webscraping reddit analyzing user behavior and top content from a marketing perspective,仅代表作者观点。)
本文数据侠 Mitchell Hung。
数据如何用于社会自省?深入挖掘数据可以得出什么样的公民社会解决方案?
本科从滨州大学历史系毕业后,他开始为《经济学人》撰写人权主题的文章。他主要关注受压迫的人群,对全球经济以及社会不公十分了解。他希望在从事数据科学工作时也能引入人文主义的视角。

DT财经与纽约数据科学学院是战略合作伙伴。DT×NYCDSA 系合作开设的系列专栏。

数据侠计划是由第一财经旗下DT财经发起的数据社群,包含数据侠专栏、数据侠实验室系列活动和数据侠联盟,旨在聚集大数据领域精英,共同挖掘数据价值。申请入群请添加微信公号dtcaijing004并备注“数据社群”,合作请联系datahero@dtcj.com。

(了解更多有趣又有料的商业数据分析,欢迎关注DT财经微信公众号“DTcaijing”,下载“DT·一财”APP)
分享这篇文章到
2019-01-04

2019-02-15

2018-12-29

2019-01-17