
这星球上最有钱的人们是什么样的?让我们用大数据一窥究竟
2019-01-04

意见
反馈

回到
顶部

Nachiket Patel 2018-03-16
在今天的媒体上,你一定已经看过太多像是”某国指控它国对其发动网络攻击”,“某公司遭遇严重信息泄露事件,数百万用户数据被盗”等涉及网络攻击事件的新闻。如果倒霉一点,你还可能就是这种恶性事件的受害者,并可能有一天打开电脑,突然发现自己眼前的屏幕被铺满了这样的字句:
“你的信息已被加密,想要恢复的话,交钱吧。”
这些都是网络攻击事件——旨在盗窃钱财、金融数据、知识产权或干扰某一目标公司的日常经营的恶意网络行动,它们绝大多数时候是由犯罪分子发动的。国家有时也会成为攻击目标,一些所谓的“政府支持的网络攻击”会尝试窃取宿敌国家的机密文件,或者仅仅是为了给对方发出一个警告信号。
据粗略统计,2015年全球因网络攻击造成的损失达到5000亿美元。是谷歌全年900亿美元的现金流的5倍还多。
在这篇文章中,我们希望通过数据分析的方式,来探究这些造成巨额损失的网络犯罪的特点,进一步了解它们的行为方式以及带来的影响。
我使用Scrapy对网络攻击事件库网站Hackmageddon进行爬虫爬取,以收集可供分析的信息。Hackmageddon从2011年开始记载各种网络攻击事件,每15天会更新一个统计表。我的爬虫对网站的目录和次级目录进行分析,不过在过程中我了解到Scrapy不如Selenium那样,能与浏览器有很好的自动化的互动。
我从2011年网站的第一张表格开始,在过程中遇到不少挑战。一个问题是,它无法自动从一个表格跳到下一个。这个网站每个页面底部有翻页按钮,我让我的爬虫对这个按钮的链接发起fetch请求,以进入下一页。另一个问题是,Hackmageddon每年都改变它的表格结构。所以我使用了控制流来解决这个问题,最终我几乎爬取了全部网站,爬取的信息包括日期、发起者、目标、描述、攻击类型、目标等级以及国别。
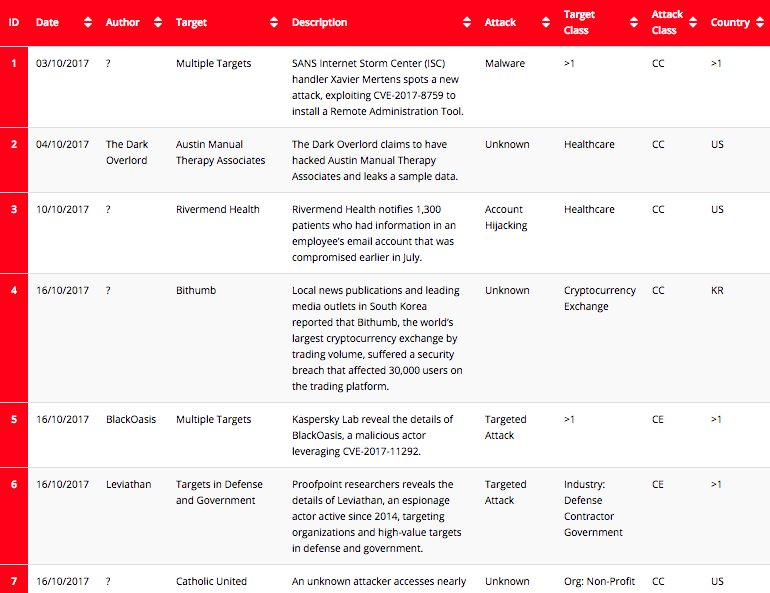
(图片说明:项目获取的部分数据)
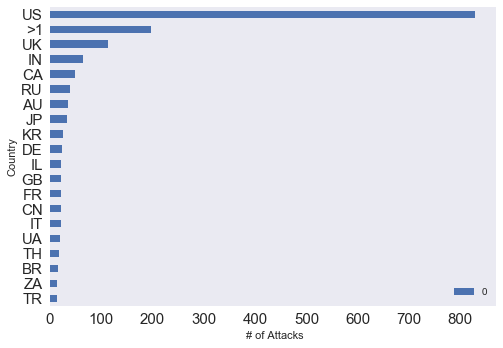
在分析数据前要先清洗数据。如我所料,爬取的数据有很多缺失。由于许多网络攻击的动机和黑客身份经常是无法知晓的,这部分的数据缺失在我预料中。我使用Python的Pandas library来进行数据清洗。在清理数据之后我开始进行可视化。最开始的简单分析揭示了一些有趣的现象。美国是受攻击最多的国家,排在第二到第四位是“>1”,英国,印度。“>1”是指“同一个黑客攻击了一个以上国家”的情况。

我爬取数据的目的之一,就是想知道这些攻击行动背后的动机。下图展示了攻击目标中不同类型的组织所占比例。政府部门和个人占据前二位置,接下来是教育机构。
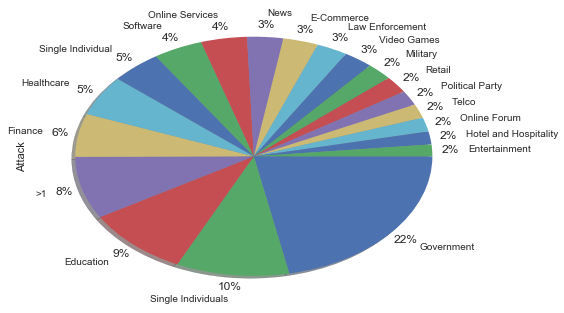
接下来的图表展示了网络攻击背后的动机。网络犯罪占比最多,达71%。网络犯罪针的典型场景是为了获取网络权限。电脑被用作武器,来发动像DoS攻击等犯罪活动。
网络间谍(Cyber Espionage)的目的则是非法获取涉密信息,尤其是政府或其他组织的保密信息。
网络战争的目的则是破坏一个国家或组织,尤其是出于军事或策略性的目的而刻意攻击信息系统。
Hacktivism就更加宽泛,它指的是未经授权进入电脑系统,并展开各种侵扰行为,从而达到某种政治或社会目的的行为。

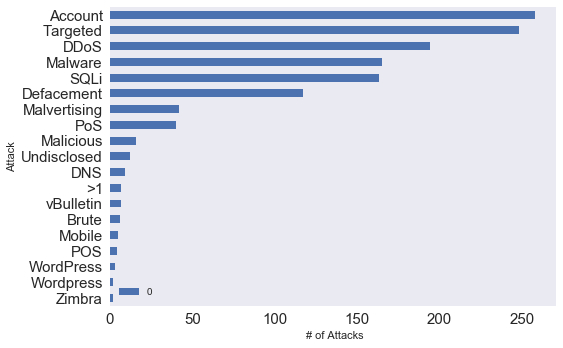
接下来的问题是,网络攻击都包括哪些类型,以及谁是最臭名昭著的黑客。
下图展示了网络攻击的类型。劫持账户、定向攻击、DDos和恶意软件占据前四。
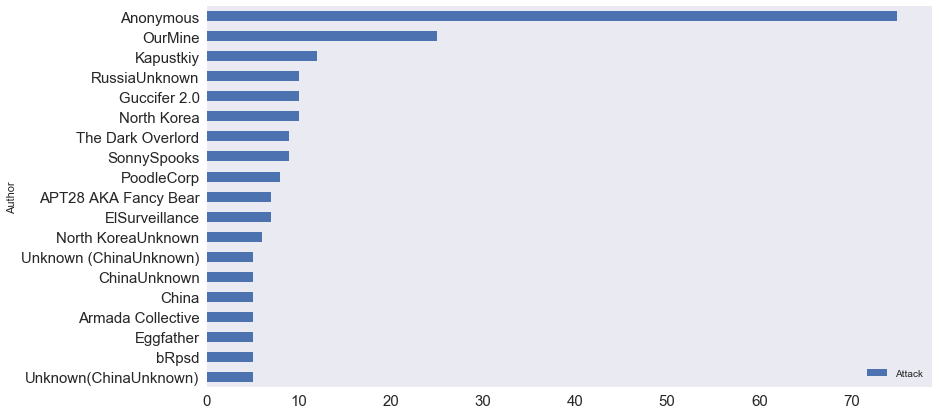
接下来的图告诉我们谁是最“有名”的黑客。排在第一位的匿名者组(Anoynymous)比第二名的OurMine多发动了75次网络攻击。
匿名者组织因其一系列针对政府、宗教团体及公司网站的DDoS攻击而出名。他们也被认为是网络世界的罗宾汉,2012年时代周刊形容匿名者是当年的“百大影响人物”。
OurMine大多数时候会将目标对准明星。被他们黑掉过推特账号的明星包括维基百科联合创始人吉米威尔斯、Pokémon Go的设计者约翰汉克、推特CEO杰克多西、谷歌CEO皮查伊以及Facebook的扎克伯格。
接下来的图表显示了各个黑客最常用的攻击方式。匿名者进行了30次DDoS,OurMine发动了20次账户劫持。

下图显示,一个名为Guccifer 2.0的黑客对美国的政党发动了9次攻击,朝鲜大多数时候在对韩国发动网络攻击。Eggfather则将在线论坛作为攻击对象,并将获取的用户信息和密码转储(Dump)。
在爬取的数据中,有很多非结构化数据。我决定对它们进行文本挖掘。我使用了Python的Scikit-learn包用于机器学习,NLTK包用于自然语义处理。
首先是词语切分(Tokenization)。Token是指符号,包括单词、词组乃至一句话。词语切分(Tokenization)就是把一段话分解成单个的单词、词组和符号等要素。在这一过程中,标点符号等标记会被舍弃。
其次是TF-IDF向量化。TF意思是词频(Term Frequency),IDF意思是逆向文件频率(Inverse Document Frequency),它们用来反映一个词在一个文档中的重要性。TF-IDF值随着一个单词在文档中出现次数的增加而形成比例增长,但同时与这个单词在整个语料库中出现的频率成反比。因为这样可以避免那些在整体上,本来就比其他单词更频繁出现的单词带来的影响。它的输出值是一个向量。
接下来余弦相似性。余弦相似性通过测量两个向量的夹角的余弦值来度量它们之间的相似性。
两个向量有相同的指向时,余弦相似度的值为1;两个向量夹角为90°时,余弦相似度的值为0;两个向量指向完全相反的方向时,余弦相似度的值为-1。余弦相似度通常用于正空间,因此给出的值为0到1之间。
然后我还使用了多维标度(Multidimensional Scaling)。多维标度的目的是对一组项目的接近性(比如相似性、距离)的范式进行可视化的程序。我将各类网络攻击事件放在图中,一些彼此相似的攻击事件会离得更近,反之亦反。这是一种非线性降维的方法。
最后是K-平均算法(K-means Clustering)。K-平均聚类的目的是:把n个点划分到k个聚类中,使得每个点都属于离它最近的均值(此即聚类中心)对应的聚类,以之作为聚类的标准。这需要将数据聚类成k个组,k是预先定义好的,随机选择k个点作为聚类中心,然后依据欧氏距离函数来将各个观察目标放置在距离它们最近的中心附近。
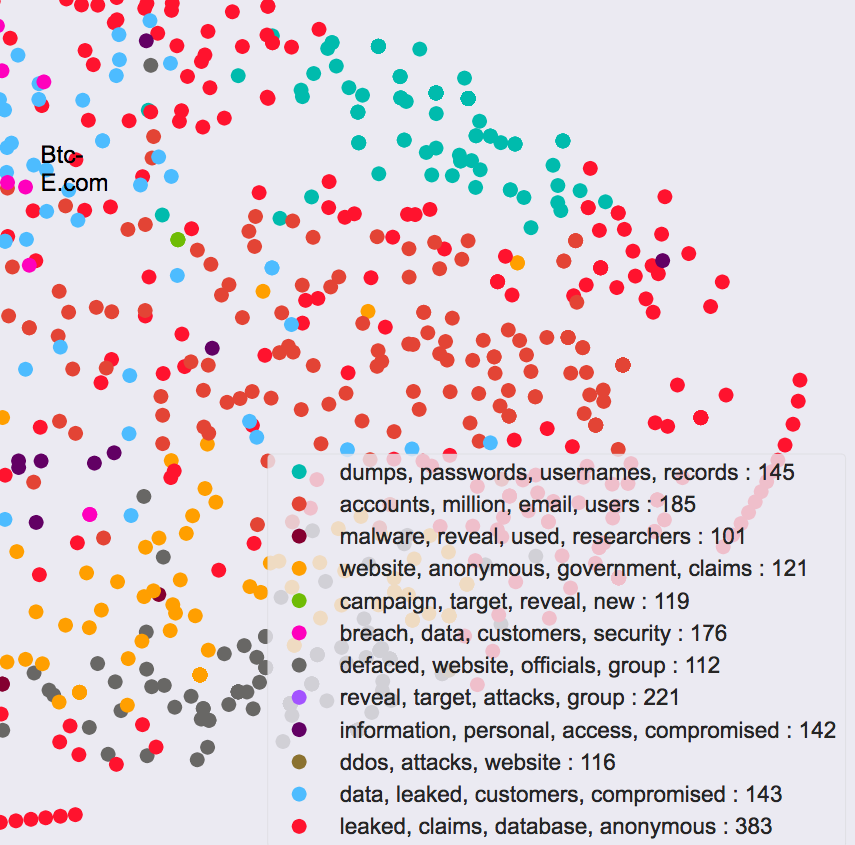
(图片说明:原图为嵌入式的D3交互,点击链接查看原图)
在我用D3做的可视化交互图中,鼠标悬浮于每个点上时就会显示被攻击的组织名称,右下角是图说,显示了每个聚类中最常出现的词组。一共有12个不同颜色标出的聚类。
比如,第一组海绿色的聚类,在图说中标出的词组为“转储、密码、用户名、记录”。
在这组聚类中,各个被攻击对象彼此相似,大多数是网站。黑客往往将它们用户的用户名、密码等进行了转储。
根据上面的可视化图表,政府组织往往会归类到7、8或11聚类,因为政府有大量涉密档案而黑客总希望将之偷走或公之于众。医疗机构则多归于6组,黑客希望获取用户数据和记录。金融机构往往在12组,因为其数据库也是保密的。在线游戏网站更经常受到DDoS攻击。
受攻击最多的是政府组织。Guccifer2.0涉及2016年大选的网络攻击行动。
账户劫持是最常见的攻击类型。
“泄漏、要求、数据库、匿名者”的这组聚类有最多的点,这说明,大多数攻击泄漏了信息,黑进了数据库,而匿名者发动了最多的网络攻击。
(本文翻译自纽约数据科学学院技术博客 Insights into the world of Cyber Attacks by Scraping Hackmageddon,文章谨代表作者观点)
Nachiket Patel拥有纽约理工学院计算机科学硕士学位,本科毕业后他做了两年软件工程师。他参加了纽约数据科学学院的课程,旨在提高自己在机器学习和大数据方面的知识和能力。

DT财经与纽约数据科学学院是战略合作伙伴。DT×NYCDSA 系合作开设的系列专栏。

数据侠计划是由第一财经旗下DT财经发起的数据社群,包含数据侠专栏、数据侠实验室系列活动和数据侠联盟,旨在聚集大数据领域精英,共同挖掘数据价值。申请入群请添加微信公号dtcaijing004并备注“数据社群”,合作请联系datahero@dtcj.com。

(了解更多有趣又有料的商业数据分析,欢迎关注DT财经微信公众号“DTcaijing”,下载“DT·一财”APP)
分享这篇文章到
2019-01-04

2018-12-29

2019-02-15

2019-01-17