
人工智能如何助力企业突围互联网运营困局?
2019-02-15

意见
反馈

回到
顶部

Zhenggang Xu等 2018-12-07
这个项目的目标是建立一个穿衣打扮推荐系统,用户可从一些 Instagram 时尚博主的图片中进行选择,我们的算法就能推荐给他们相似风格的衣服,并且获得比图片中款式更加实惠的价格。
用户选择了照片后,我们就会从我们的网站(fashion-rec.com)的库里有的电商网站上给你推荐对应的衣服。

时尚界的KOL增加很快,变化也很快。他们是流量的掌控者并对大家的购物行为有很强的影响力。根据mediakix的数据,广告主仅仅是为Instagram平台的广告就支付了16亿美元。
广告主会给他们广告费,让他们穿着自家品牌的衣服拍照上传到Instagram,并且要提到这个品牌。这是品牌商常用的广告方式,希望关注博主的用户会购买他们的衣服。我们的推荐系统似乎有些与此为敌的意思,但我们最终是帮助了消费者,提供更多选择。
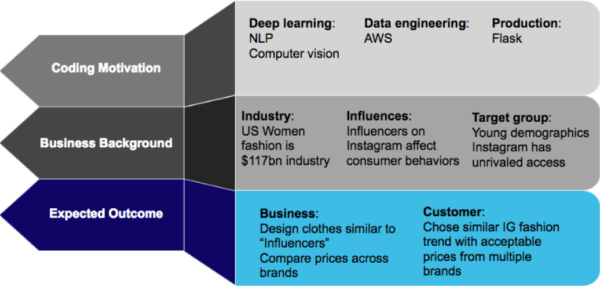
我们使用了敏捷(Agile)的项目流程来完成我们的终极项目(Capstone Project) 。这包括使用机器学习模型进行训练以及在不同组员同时开发 Flask 应用。
下面是把所有元素结合在一起的流程:
1 从梅西百货、H&M、ASOS、Bloomingdales、Fashion Nova这五个网站爬取了女士裙子和上衣的数据;信息包括产品名称,价格,产品描述以及图片
2 爬取了13个Instagram意见领袖过去6个月的点赞,点评,以及帖子数据
3 使用NLP的潜在狄利克雷分布方法,将爬取的产品描述归类为6种不同的风格
4 我们尝试了基于FGVC5(一个有1014544无偏衣服图片以及228个品类标签数据的kaggel图片数据库)的iMaterialist Challenge (Fashion)
5 我们从上面分好的6个风格类别提出图片,使用步骤4的方法找到与意见领袖们发的图片相似的产品
6 我们开发了一个Flask 应用,可以给用户提供交互功能,并能让用户无限的提交搜索请求,对意见领袖的图片和我们的主要产品销售渠道的库进行搜索(建在亚马逊云AWS上)
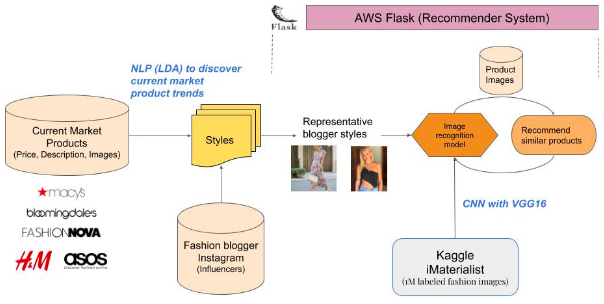
我们有约10000个产品信息,约1000份IG(Instagram,以下简称IG)的数据。不同产品价格中位数从150到20美元。
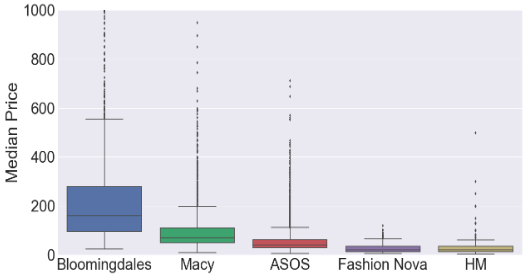
大多数的产品来自ASOS,基于可负担的价格区间,以及衣服的风格多样性。
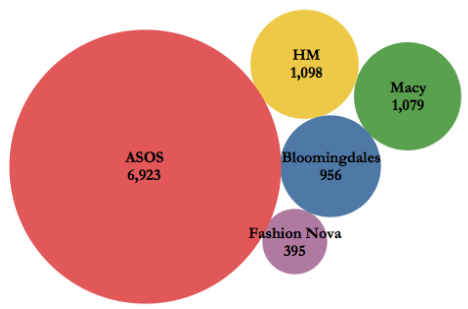
每个不同时尚博主的帖子数据如下,平均的发帖频率在每月5到20帖子。
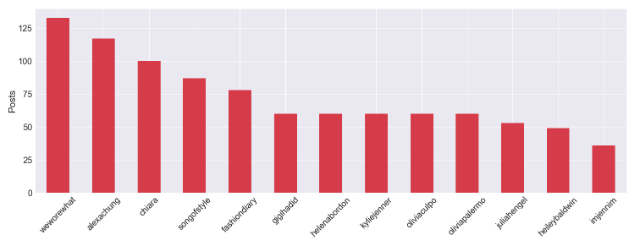
每个帖子的点赞数的中位数反应了受欢迎程度,其中号称全球第一大网红的Kylie Jenner比中位数多出来600万(即为平均每一张图有600万点赞),所以下图没有包括她。
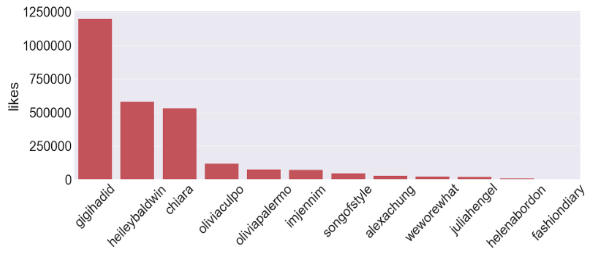
我们的数据库里点赞数很高,说明大家被博主推荐的衣服吸引,我们的平台能让大家根据他们的喜好找到类似的衣服。
1.NLP
我们将NLP(自然语言处理技术)应用到分析产品描述上,从而发现当下市场的流行趋势。NLP发现的风格之后会用来区分不同博主的风格,并且保证它们可以在市场上购买到。
基于预测和基于频率的方式是两种最常见的NLP 方法。基于频率的方法假设文档中的词语彼此独立,只会考虑出现的频率。相反,基于预测的方法会考虑单词共同出现的情况,在处理有很强的单词间关联的文本时,它有优势。
Word2Vec 和 Doc2Vec
我们使用了两种方法来比较他们的效果。对于基于预测的方式,我们试了这两种方法Word2Vec 和 Doc2Vec 来生成每个产品描述文字对应的矢量,之后使用K-means基于矢量距离来将产品分类成不同的风格类别。
对于Word2Vec 分析,词语的矢量来自一个提前训练好的Word2Vec 模型(可以在Github上找到)。对不同的单词矢量进行平均,得到代表某一个物品的描述文字的单一的矢量。对于Doc2Vec,我们基于一个使用我们的物品描述文本为数据,用Gensim进行训练的Doc2Vec模型来得到相应的矢量。
使用Doc2Vec的矢量得到前十个最相似矢量中更加相似的物品图片。我们决定使用Doc2Vec生成的矢量来进行K-means算法执行,将物品描述按照它们的矢量间的余弦距离分成六个不同组别。基于预测的方式这一次表现并不理想,从K-means算法得出的 t-SNE图并没有显示出不同组别之间的明显区别。一个可能的解释是,产品描述的文本是由关键词组成而非彼此联系紧密的句子。

Latent Dirichlet Allocation (LDA)
另一方面,基于频率的方法,尤其是Latent Dirichlet Allocation (LDA) 潜在狄利克雷分布显示出了更好的结果。作为最知名的话题模型,它将所有单词以及他们出现的次数作为输入,然后尝试在没有打标签的文档中找到结构或者话题。话题模型假设单词的使用与话题出现相关。每一个话题指的是不同词语的组合,它们有不同的权重,而每一个文档又是不同话题的组合。
在我们的项目里,文档就是物品描述,而话题指的是不同关键词描述出的不同时尚风格。对于每一个产品,得分最高的那个风格就是它对应的风格种类。
一个问题是,我们并不知道我们收集来的零售网站数据里有多少种不同的风格。我们多次尝试后认为6会是个合理的选择。因此也会存在其他的可能,而且这也正是无监督聚类问题的美丽之处。
分组完成后我们使用t-SNE来进行更好的可视化,它能起到对数据降维的作用,从而让我们得到二维图。在下面的图里,所有产品被分为六种颜色。左上角为对应的关键词。从图可以看到,这个算法成功对所有产品进行了分类。这些关键词有更多的信息并能更好地反映出这些产品的风格。

2.图像分类
我们应用了深度卷积神经网络算法,以及提前训练好的imageNet(VGG16)来进行一个多类别的分类,分类的对象是最近Kaggle比赛中已经打好标签的上百万时尚图片。借此,我们得到了我们的第一版图像识别模型。与余弦相似衡量方法结合,这个算法可以推荐线上购物平台。
Kaggle 数据库
训练数据来自228个时尚属性类,它们每张图都拥有多个标签。总计1014544张图片用于训练,10586张用于确认,42590张用于测试。我们的项目并没有用kaggle 数据库里的测试图片。
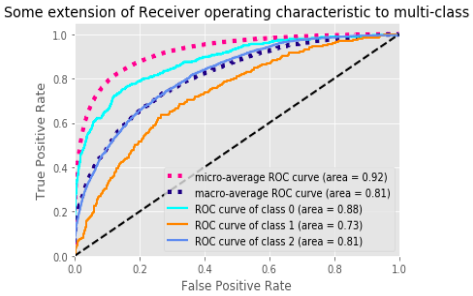
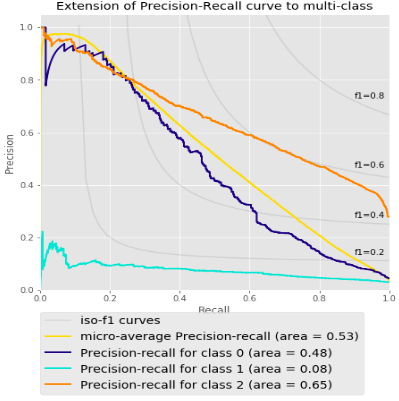
模型表现
验证数据组整体的ROC和PR曲线。整体的表现不错。然而,也有一些标签表现不好。下一阶段我们希望能更直观的用可视化的形式看到模型表现究竟如何,因此我们将模型放在AWS上。
AWS
我们项目的最终产品是叫做 Fashion-Rec 的网站,搭建在AWS上,使用Flask应用。首页包括有影响力的时尚意见领袖们的图片,供用户选择。
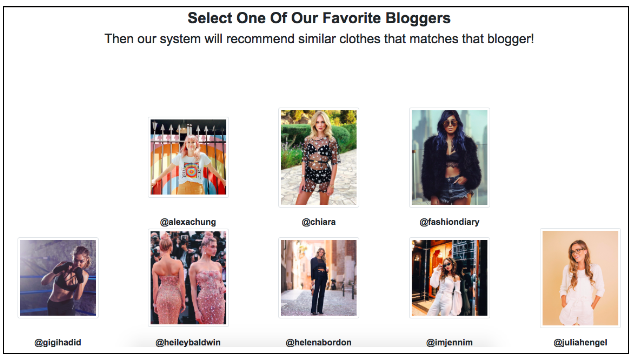
当用户点击其中任意图片,网站会跳转到另一个包括这个特定博主的图片的网页。算法会通过NLP分析来将每个博主的图片分类成5-6种服装流行趋势类别。
这能保证用户有足够多的选择。下图是一个具体例子,可以看到六种不同的分类。
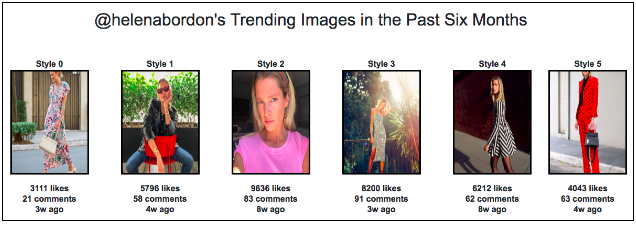
比如,当你选择“风格0”,系统会自动生成风格类似的衣服,并且是在我们数据库里的网站上可以买到的。用户还可以继续点击“相似物品”,系统也会不断推荐新的产品。

为了进一步丰富用户体验,我们还会在页面上显示与用户倾向最不一样的衣服。这样,当他们想要换一种风格尝试,他们可以轻松地把这些产品直接添加到购物车里。

注:本文编译自纽约数据科学院文章Fashion Rec.。
Kelly Ho毕业于康奈尔大学,拥有工程学硕士。她曾在Sanofi Genzyme 从事研究分析,统计模型等工作,并为制造生产过程提供从数据角度出发的改进意见。
Richie Bui 过去3年在Medtronic 的工作经历让他在收集、处理和捕捉大量数据集方面拥有丰富经验。
Samuel Mao 是一名数据科学家,他在使用R和Python开发模型解决商业需求方面拥有三年的实践经验。他在中美跨境贸易方面也有丰富经验。
Silvia Lu 在纽约和新泽西港务局实习,担任数据分析师。
Zhenggang Xu 是纽约数据科学学院的一名数据科学学者,他在深水探索领域工作多年,并拥有计算化学专业学位。
DT财经与纽约数据科学学院是战略合作伙伴。DT×NYCDSA 系合作开设的系列专栏。

数据侠计划是由第一财经旗下DT财经发起的数据社群,包含数据侠专栏、数据侠实验室系列活动和数据侠联盟,旨在聚集大数据领域精英,共同挖掘数据价值。申请入群请添加微信公号dtcaijing003并备注“数据社群”,合作请联系datahero@dtcj.com。

分享这篇文章到
2019-02-15

2019-01-17

2019-01-08

2018-12-29