
人工智能如何助力企业突围互联网运营困局?
2019-02-15

意见
反馈

回到
顶部

编辑 | 程一祥 2018-05-24
在上篇文章 《Facebook效应:让信息在社交网络中流行起来,真的重要么?》里,我们已经证明在 facebook (以下简称FB)上流行的重要性。想要获得更好的公众曝光,就要在FB上流行,这说起来比做好要容易许多。所以现在我们来试着分析一下,如何做才能更好地在FB上流行。我们可以从FB的流行趋势的一些基本原则着手,看看如何可以让内容得到最大化的曝光。
与我们所想的相反,造成“流行”并不是用无尽的帖子和图片,狂轰滥炸地淹没信息流。FB用户在浏览内容时常常会忽略帖文、图片,尤其是广告。他们只会被吸引眼球的事情抓走注意力,这也是许多营销公司在做的。
一个最好的案例就是新闻机构在FB上分享内容的行为。与用户访问新闻网站获取信息的行为方式彻底相反,在FB上用户不是来看新闻的,因此新闻机构在FB上并非逐字逐句搬运,而是重新撰写推荐语,试图吸引FB用户的注意,继而吸引用户去到他们的网站。
为了弄清楚如何撰写帖子和内容才可以提高FB曝光率,我对纽约时报进行了案例分析。
我爬取了FB上纽约时报从2012到2016年发的所有帖子,这些数据包括FB帖子内容、分享的文章或视频题目、相关描述、以及点赞数。
我发现的第一个明显现象,是FB上的帖子和纽约时报网站上的文章,在简介上有明显的不同:他们在FB上发帖时的简介会更长。


从图中代表平均数的虚线可以看出,在FB上发帖时,单词和字母都会更多。P值都少于0.001。这是否说明较多的文字更适合引发流行?
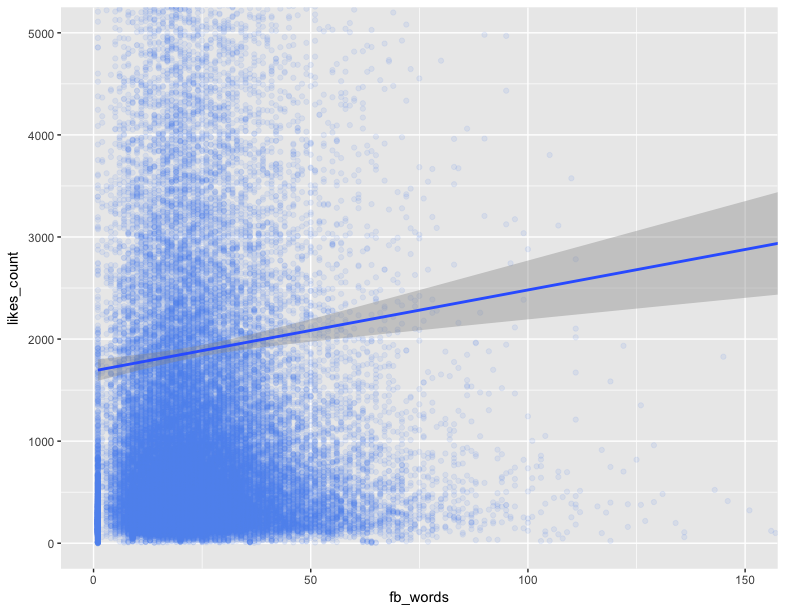
我接着又做了一个用词数量与点赞数关系的散点图,如上所示,两者呈正相关关系。
那么除此之外,在FB上的用词又有什么区别呢?
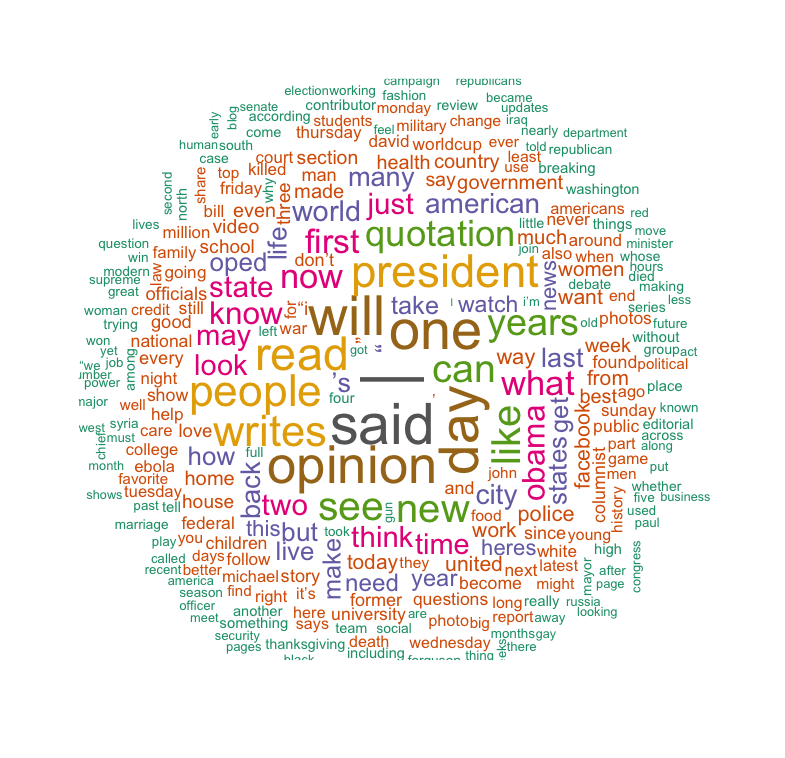
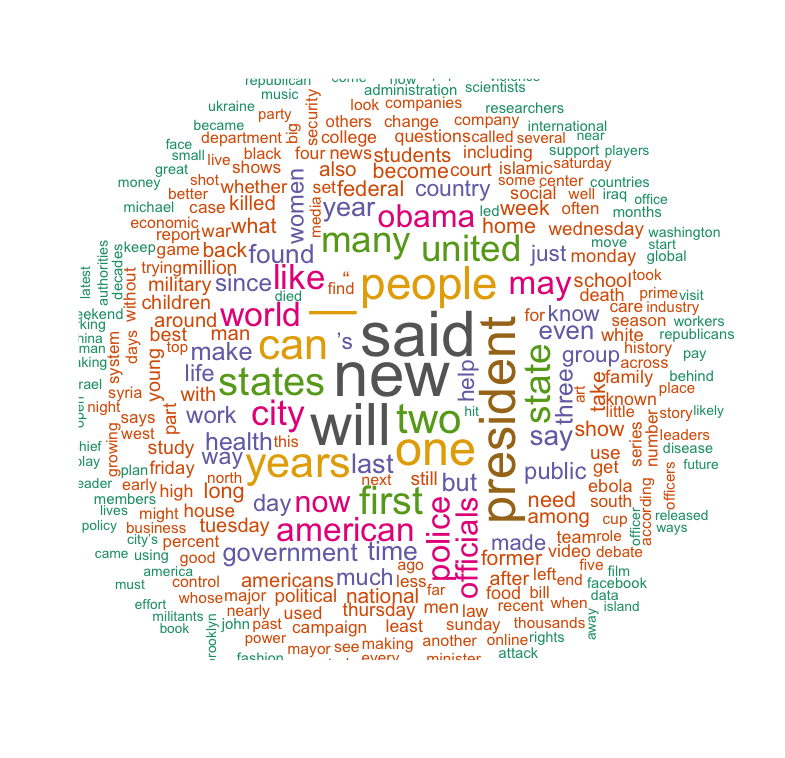
如果仅从词云的角度来看,如我们所料,FB与官网上的用词大部分相似。所以,我们接着使用谷歌的云端自然语义平台进行分析,以找到更细微的区别。
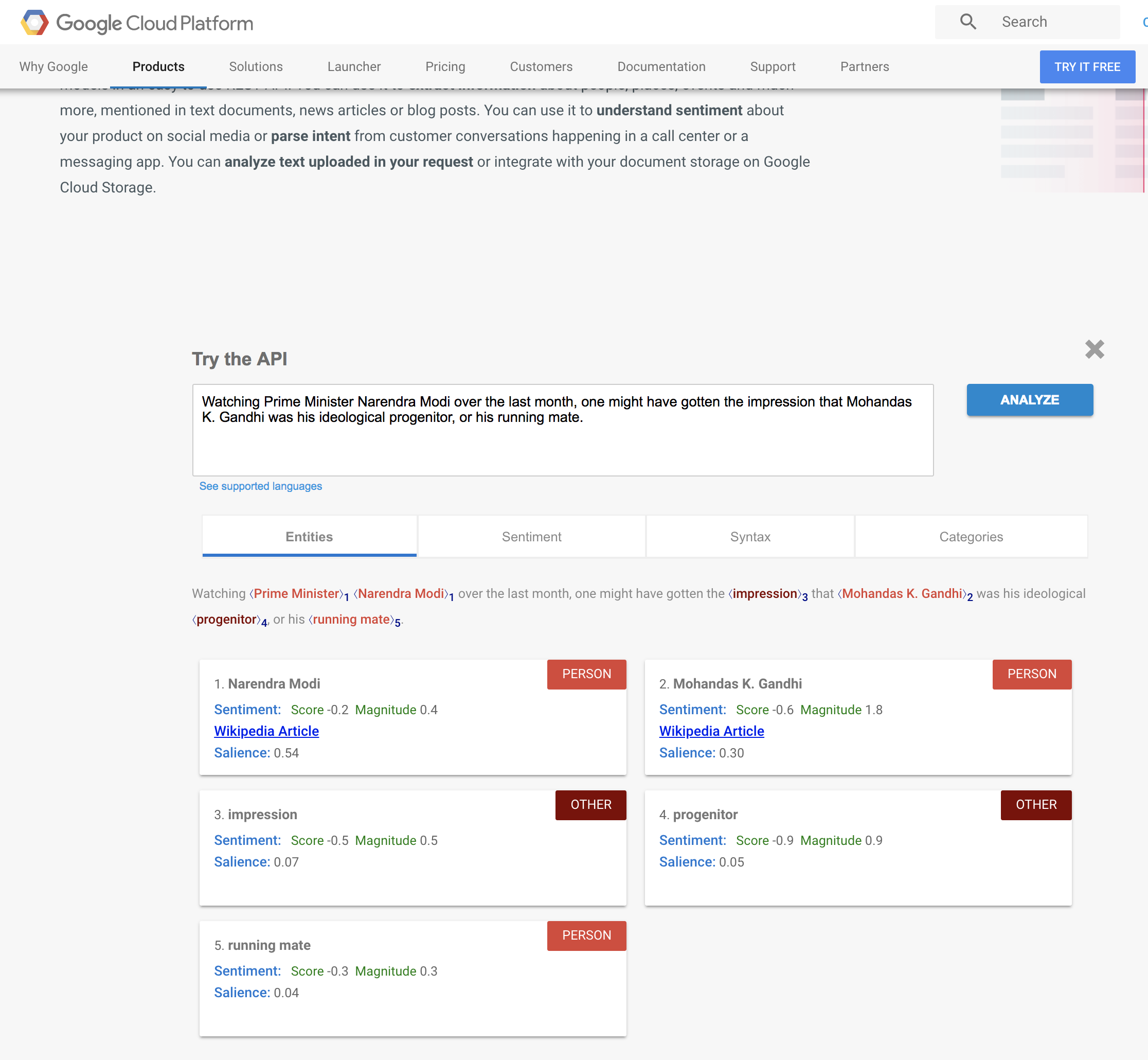
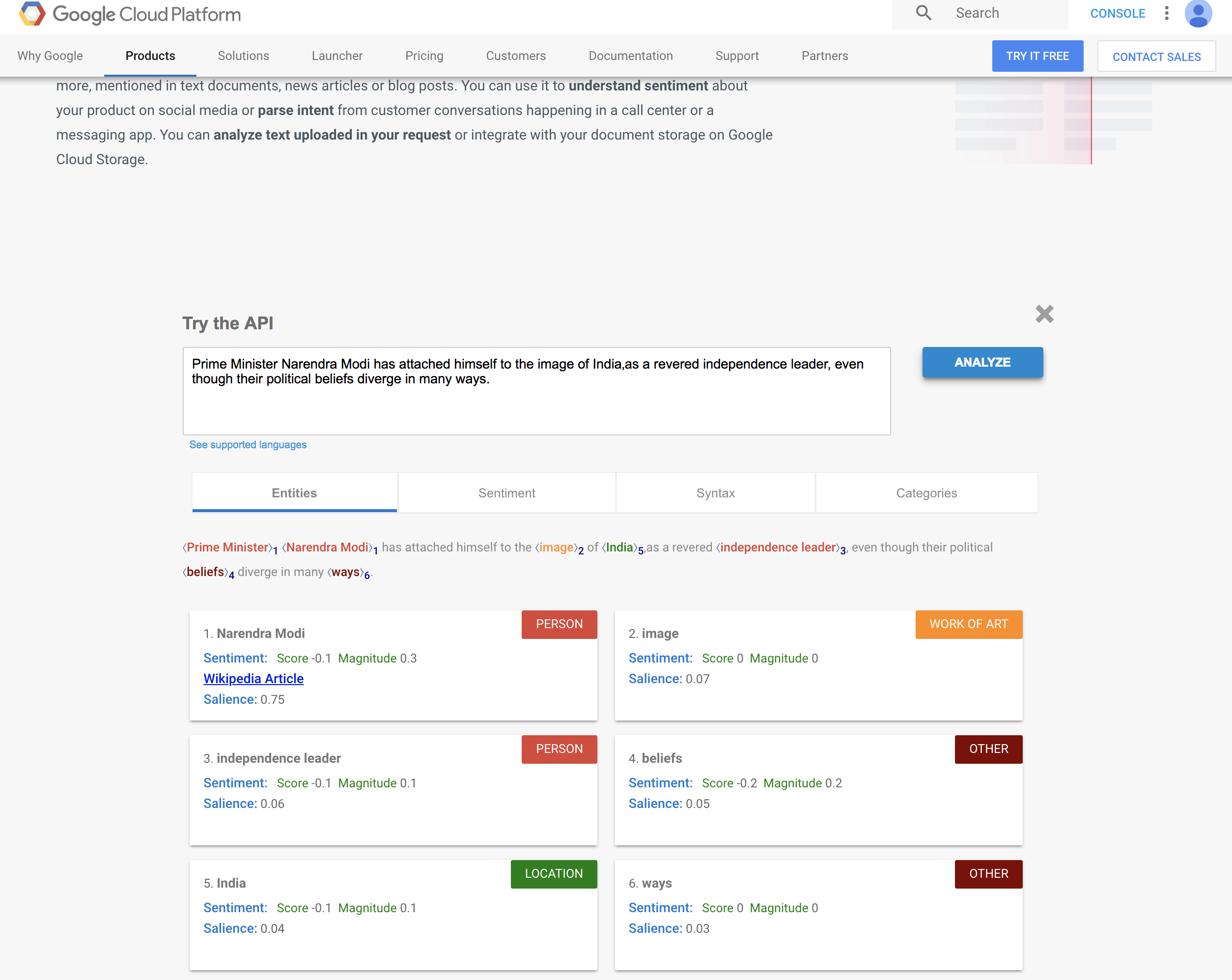
上图是一组对比。我们可以看到,在这个案例中,FB上的帖子提到了甘地,而网站上的摘要没有。尽管这只是一个简单的例子,但这种模式在整个语料库里也十分明显。当在FB上发帖时,纽约时报非常明显地喜欢提及人名,诸如奥巴马、罗姆尼等。
另外,在FB上发帖时,纽约时报使用问句或者引语的次数是网站的5倍。
所以,总的来说,我们这个对纽约时报的开放分析,研究了纽约时报如何在FB将社交媒体曝光最大化,并获得了一些启发。这包括:第一,与主网站相比,使用更长、更偏叙述的帖子;第二,使用更吸引人的词语,比如总统等,并且具体地指向能让人产生兴趣的人,如奥巴马等;第三,给读者提问,同时使用一些惊人的引语来吸引读者。
在Kylie Jenner的推特之后,Snapchat的市值大约损失了16亿美元。她的推特是造成这一切的全部原因么?我们也许永远也不知道。但是我们可以确定,Jenner在社交媒体上的超强存在感,严重影响了Snapchat的前景。
的确,在这项目中,我尝试解码社交媒体上,尤其是FB平台上,一个内容流行会带来什么。我发现,当一个话题在FB上流行,它会导致其对应的维基百科搜索量提升70%。把维基百科的页面浏览量看作是识别度上升的某种标志的话,可以看到FB曝光度对产品识别度有巨大的影响。
而且,为了确定这个识别度的上升就是由FB平台带来的,我还对比了在FB上流行,与在推特上流行的不同结果,并发现后者带来的影响并不明显。这给我的假设提供了支持。
接下来我对纽约时报在FB和自己网站上发文章时的不同处理方式进行对比,来研究它是如何提高FB等社交媒体平台的存在感。我发现,在FB上的帖子更长,并且会更多地包含人名,并且倾向使用更多的问句和引语。
我的这个项目本质上还是探索性质,所以未来可以进一步做的研究包括:撰写一个脚本,从而持续地爬取FB上流行话题的帖子信息,从而可以在不同时间节点进行更详尽比较;提高我的样本量,让它足够运行固定效应模型(fixed effects models),进而衡量一个话题在流行前和流行后的变化;使用更多的自然语义处理工具,比如潜在狄利克雷分布 (latent dirichlet allocation)等,对FB上和其他网站上发帖时的文本差别进行更深度的分析。
(本文编译自技术博客 The Facebook Effect,仅代表作者观点。)
本文数据侠是William Kye,喜欢用数据解决问题。他拥有美国圣母大学社会学博士学位,对分析和理解人类行为有浓厚兴趣并富有经验。Kye不只将数据看作生硬的数字,他还希望将其置于人类社会行为的大背景下进行理解。他此前做过大量的人口数据与其他数据的交叉分析,比如社区自杀率与种族构成的关系,私立学校的数量与社区士绅化趋势的关系等。Kye掌握R语言、Python等,同时希望将数据分析以有洞见的故事形式展现出来,并将自己的能力用在解决现实世界的难题上。

DT财经与纽约数据科学学院是战略合作伙伴。DT×NYCDSA 系合作开设的系列专栏。

数据侠计划是由第一财经旗下DT财经发起的数据社群,包含数据侠专栏、数据侠实验室系列活动和数据侠联盟,旨在聚集大数据领域精英,共同挖掘数据价值。申请入群请添加微信公号dtcaijing004并备注“数据社群”,合作请联系datahero@dtcj.com。

分享这篇文章到
2019-02-15

2018-12-24

2018-12-07

2018-12-28