
人工智能如何助力企业突围互联网运营困局?
2019-02-15

意见
反馈

回到
顶部

作者 | Amy Tzu-Yu Chen 2017-11-16
我们都有各自的爱好。爱ta,就要拥有ta嘛,所以有人狂刷eBay和古董店收集各种老式海报;有人在Footlocker外面通宵排队,只为抢到一双限量版篮球鞋。
有时这种爱好并不能得到所有人的认可,认为耗费大量时间和金钱收集看起都差不多的东西,还蛮疯狂的。
当然了,我的爱好我做主,不管你爱好什么,喜欢收藏什么,你都能在身边或是网路上找到志同道合的朋友,共同爱好者的社区,在那里大家都有着共同的语言。
有这么一群人,他们是星巴克马克杯的狂热爱好者,自称为“muggers”,活跃在Facebook,eBay和其他在线社交平台,积极地从世界各地的其他收藏者手里交换或购买自己想要的星巴克马克杯。
我个人也是个杯子控,并且对和我有相同爱好的人们感到好奇。他们都在哪儿?藏品数量是多少?现在最in的是哪一款?
所以我想使用网络抓取,数据可视化和K-means聚类算法<K-means clustering>(非监督学习算法),对全世界的星巴克爱好者们进行研究。
Fredorange.com,最大的星巴克爱好者社区在线平台之一,是由一个奥地利星巴克杯收藏家创建的网站,目的是为广大星巴克控们提供一个分享有关星巴克产品的信息的平台。
Muggers也可以在这个网站进行交易。无论是刚被种草还是骨灰级的星巴克粉丝,无论是想指导星巴克最新产品的发布信息或想炫耀一下自己的藏品,Fredorange.com都是世界各地星巴克粉丝们的第一选择。
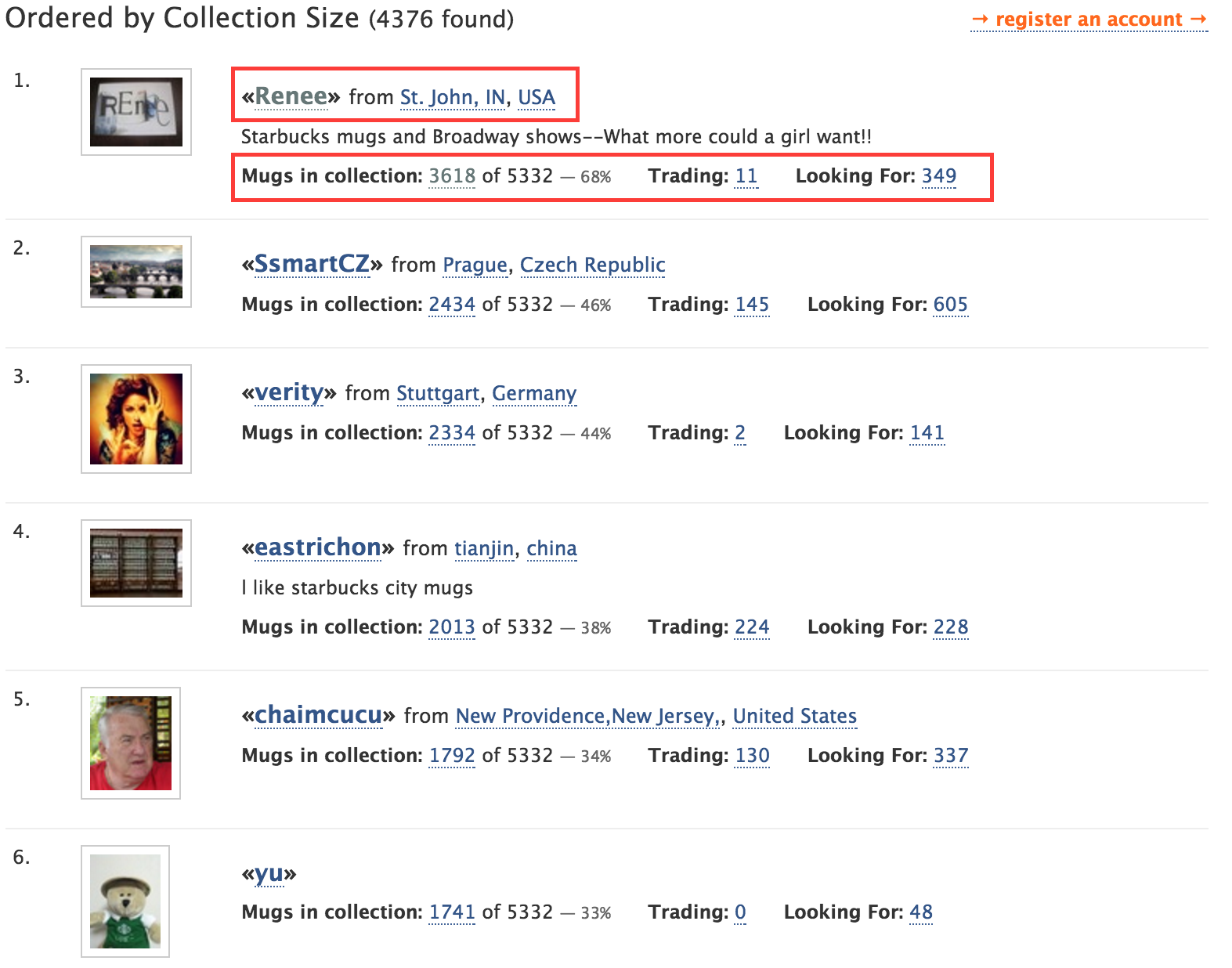
根据Fredorange.com记录,星巴克迄今为止发行了5506款马克杯,排名第一的mugger,已经收集到了其中的3698款。
为了可视化这些信息,需要从Fredorange.com上对以下信息进行抓取,创建一个星巴克马克杯和收藏者的数据库。
首先是马克杯:姓名,城市,国家,版本,拥有者数,寻求者数,交易者数。

其次是用户数据:用户名,城市,国家,拥有马克杯的数量,想入手的杯子数量,曾经的交易数量。
使用Python的BeautifulSoup和pandas包,我从Fredorange.com中抓取了所需的信息。
数据清理是很有必要的一个步骤,可以让我们得到更真实更准确的数据。
由于Fredorange在注册帐户时没有城市和国家/地区的选项,而是需要用户手动进行输入。这导致,用户信息中的城市和国家有许多拼写错误,不同拼写,或使用了英语以外的语言进行填写。此外,一些用户仅填写了自己所在的城市,国家这一项是空白,所以我们还需要通过其所在城市弄清此用户位于哪个国家。
我还创建了一个Shiny App,以求更直观的了解这一群体,还能可视化各款马克杯的市场行情。
这个App由以下四部分组成:
Geography:星巴克马克杯的原产国和爱好者的地理分布的地图。
K-means Clustering: 基于K-means算法的马克杯。
Collectaible Editions: 显示不同版本马克杯的稀有度和流行度的散点图。
Collectible Country: 不同原产国马克杯的稀有度和流行度的散点图。
我们可以看到星巴克产品和爱好者的地理分布。美国拥有最多的产品和爱好者,毋庸置疑。在地图中选择“...不包括美国”("... excludingUSA")这一项,还能可视化美国以外的收集器和产品的地理分布。
下图是在美国以外的星巴克马克杯收藏者的地理分布图。我们不难发现,收集星巴克马克杯在加拿大,西欧地区和东亚地区也相当的受欢迎。
让人略感意外的是,德国的muggers的数量超过了加拿大,排在在美国之后。

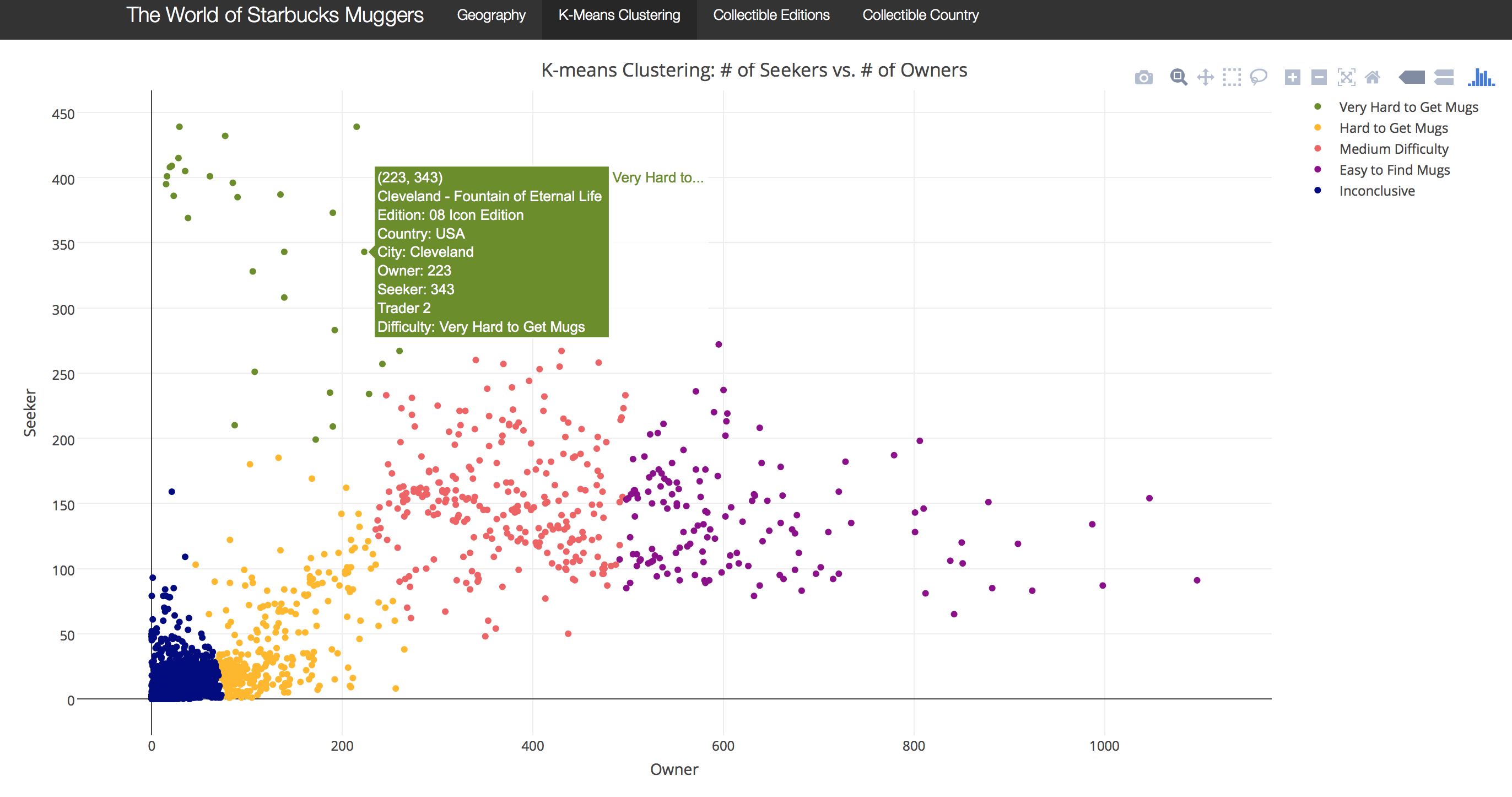
第二步我使用了K-means聚类算法处理收集者,求购者和交易者数量等数据。 k的选择基于对不同k的群内方差的检查。参数nstart设置为100,代表算法在选择最低的群内方差之前将运行100次。
下图显示了基于K-means算法的马克杯排名系统,横坐标代表拥有者的人数,纵坐标为收藏者的人数。为让我们能更有效地了解每个杯子的价值,我们将各种马克杯分为了5类,紫色代表容易收集到,红色代表有一定收集难度,黄色代表很难买到,绿色代表这款杯子非常稀有也很难收集到和蓝色代表稀有程度不确定。(K均值聚类是一种无监督的算法,因此排序系统不是分类模型。)
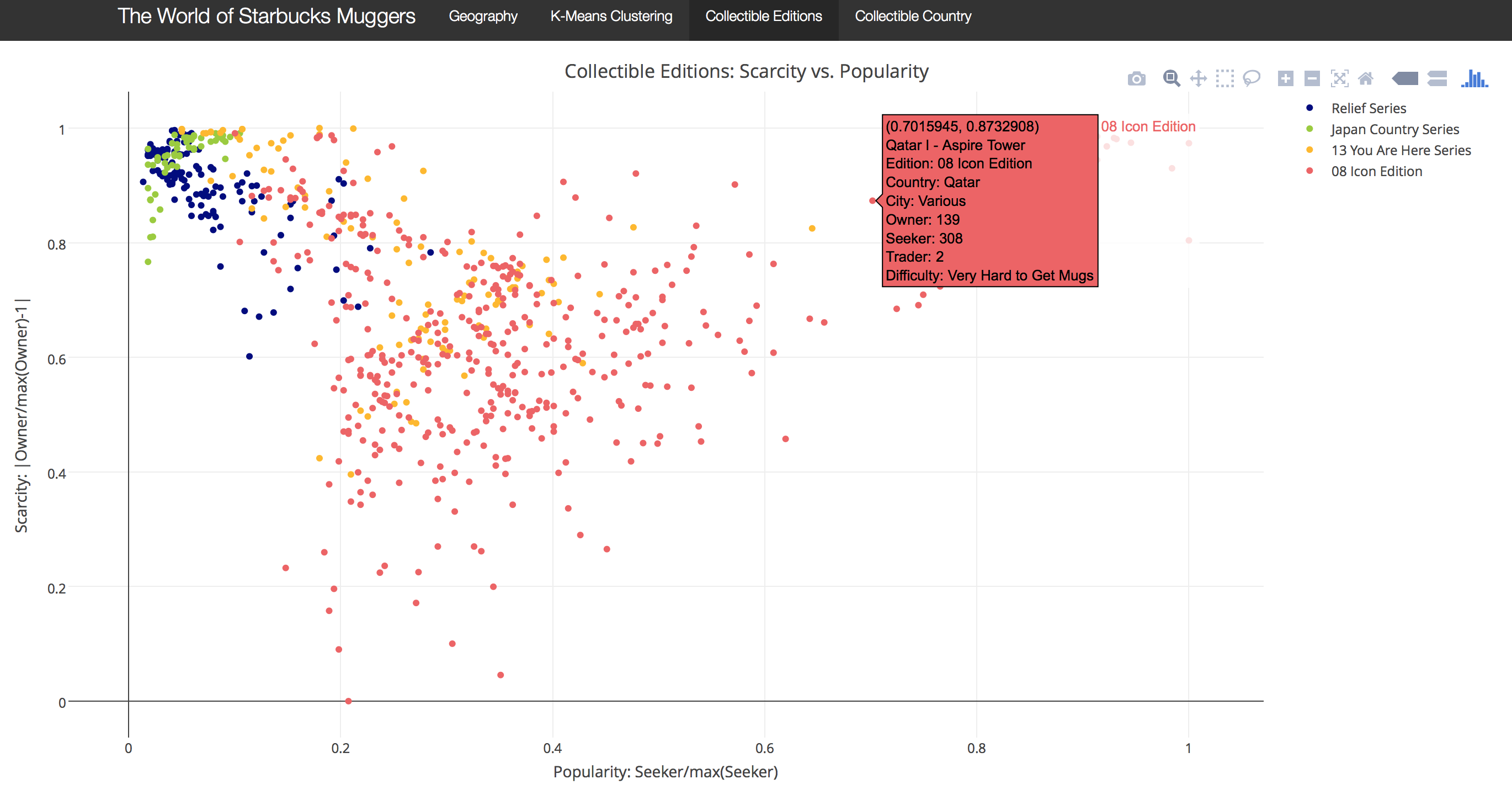
Shiny APP的最后两个选项卡,我选择了四个版本和六个国家/地区来进行研究。大家可以仅选择版本或感兴趣的国家来可视化每个杯子的供应和需求。将鼠标悬停在每个数据点上,即可查看杯子的详细信息。
下图是不同版本马克杯市场行情的散点图。使用来自寻求者和所有者的两个新变量来帮助可视化流行版本和原产地的杯子的供应和需求。横坐标代表Popularity,受欢迎的程度,根据希望收藏这款马克杯的人数来衡量,数值越大,说明想要这款杯子的人越多。 纵坐标代表Scarcity,稀有程度,数值越大代表拥有这款杯子的人越多。从图上我们可以看到,人气高且收集人不多的杯子很可能是很难找到杯子。而人气不高,发行量大的杯子则很容易找到。
本文使用了python的BeautifulSoup、pandas包,以及R的shiny、dplyr、plotly、countrycode包。
整个过程均有详细代码,欢迎访问作者原文查看。
DT×NYCDSA 是DT财经与纽约数据科学学院合作专栏。

关于纽约数据科学学院:
纽约数据科学学院(NYC Data Science Academy)是由一批活跃在全球的数据科学、大数据专家和SupStat Inc. 的成员共同组建的教育集团。
本文作者Amy Tzu-Yu Chen,加州大学洛杉矶分校(UCLA)统计学学士,辅修德语、日语和城市/地域研究。喜欢运用统计分析,机器学习技术和批判性思维来解决问题。

数据侠计划是由第一财经旗下DT财经发起的数据社群,包含数据侠专栏、数据侠实验室系列活动和数据侠联盟,旨在聚集大数据领域精英,共同挖掘数据价值。申请入群请添加微信公号dtcaijing002并备注“数据社群”,合作请联系datahero@dtcj.com。

(了解更多有趣又有料的商业数据分析,欢迎关注DT财经微信公众号“DTcaijing”,下载“DT·一财”APP)
分享这篇文章到
2019-02-15

2019-01-08

2018-12-07

2019-01-04