
让数据科学赋能金融风控 | 数据科学50人·沈赟
2019-08-30

意见
反馈

回到
顶部

陈静 2018-09-13
“思考如何将最前沿的研究、技术进行普及应用,发挥出它们的影响力,是我最看重的事。”戴金权这样谈论自己的技术观。
戴金权是英特尔的高级首席工程师、大数据技术全球CTO,负责领导英特尔全球(位于硅谷和上海)的工程团队在高级大数据分析(包括分布式机器学习和深度学习)上的研发工作。
他带领团队研发了基于Apache Spark 框架的分布式深度学习库 BigDL,并在此基础上构建了大数据分析和人工智能的平台Analytics Zoo,致力于将AI技术普世化,让AI技术离大众更近一点。
从学生时代开始,戴金权就对计算机科学的综合系统有深刻的认识。他的本科和研究生阶段都投入到了计算机科学之中,对于自己热爱的学科,戴金权有自己独到的理解。他认为,计算机科学是一个综合系统,包含了编程,微积分、线性代数、离散数学等知识,计算机系统更是其中非常重要的一部分。
“计算机理论很多时候涉及到的是计算复杂度问题,也就是通过一些数学方式理解各种计算机的算法设计,这跟数据科学要求将各种技术综合应用是相似的。”戴金权说道。他认为数据科学是很多不同领域的交叉,结合了计算机科学、数学、概率统计等学科,而计算机科学也是一个比较综合的系统,因此成为数据科学中非常重要的一环。同时,他认为数据科学某种意义上来说是一种应用科学,重在解决问题;数据科学家需要具备综合的能力,能够将不同的技术应用到具体问题中去。

由于成绩出众,戴金权在复旦大学的本科时期获得了英特尔奖学金。英特尔奖学金设立于1998年,旨在激励大学生在信息科学与工程技术前沿领域的创新,在业界和学业都颇具影响力。
“因为有幸拿到了英特尔奖学金,所以对英特尔很有感情。”
英特尔奖学金在戴金权心中埋下了技术梦的种子,激励着他在技术道路上不断探索,也在冥冥之中影响了他之后的职业道路。
2002年7月,从新加坡国立大学研究生毕业后,他加入英特尔成为了一名软件工程师。谈到加入英特尔的原因,戴金权说道:“英特尔在中国设立的研发机构能做非常多核心的技术研发,里面也有很多特别优秀的技术人员,能够领导全球的技术发展,这是非常吸引我的地方。当然还有之前的奖学金经历让我对英特尔很有感情。”

戴金权希望在英特尔能够进行更多计算机技术的创新和探索。
最开始,戴金权的团队是由三位初出茅庐的毕业生组成的,这个年轻的团队为当时最先进的网络处理器芯片,做出了世界上第一款真正商用的大规模自动化并行、异构计算编译器。2001年,美国在完成“蓝色选择”、“白色选择”系列核模拟计算机之后,一度停止了高性能计算机的研制,戴金权团队在并行计算编译器上的突破意义非凡,并行计算渐渐成为提高计算机系统性能的主要手段。戴金权本人在这个项目中获得了二十多项国际专利,并且在PLDI上发表了当时第一篇主要工作在中国大陆完成的论文。(DT君注:PLDI是程序设计语言与编译技术领域最重要的国际会议)
几年之中,团队成员从最初的三人成长为二十多人,戴金权作为项目的首席架构师经历了整个产品周期,针对战略客户发布了多个产品,这一过程中他也见证了编译器技术逐渐发展成熟的过程。不过,戴金权并不满足于只做编译器,他一直在思考下一个技术方向在哪里。
2008年左右,随着互联网的发展,很多企业面临着数据量不断增大而无法有效存储和处理的问题。戴金权敏锐地发现了业界对大规模的数据存储处理技术的潜在需求。经过技术调研,他发现之前自己做的大规模并行计算技术与大规模的数据存储处理技术在很多方面是相通的,踌躇满志的他决定带领团队在开发一个大数据平台。
同年,由Apache基金会所开发的分布式系统基础架构Hadoop开始开源,但是当时在国内很少人使用这一技术。戴金权带领的研发团队配合产品团队,做出了Hadoop在国内的发行版,一起为英特尔争取到了第一批有大数据技术需求的客户,解决了中国联通、中国移动等企业的面临的大数据存储、处理难题。
戴金权领导了英特尔全球的大数据技术长期规划,因为他和团队的持续努力,英特尔开始逐渐重视起大数据方面的业务,并且增加了在上面的投入。
随着Hadoop被广泛使用,大规模的数据存储处理问题逐渐被解决,戴金权开始思考:业界面临的下一个需求是什么?
他观察到:有了大规模的数据以后,业界将不再满足于对数据库进行简单的查询,而会需要对数据做一些更加高级的分析,比如实时的流式分析、图像分析和机器学习。但是当时的Hadoop平台并不能实现高效率的高级分析任务。
“业界对大数据技术的潜在需求,就是技术下一步的发展方向。”戴金权开始思考如何用新技术来解决这一新的挑战。
2011年,戴金权团队与加州大学伯克利分校的AMPLab开始在Apache Spark平台上合作开发。(DT君注:Apache Spark是一个围绕速度、易用性和复杂分析构建的大数据处理框架,最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apache的开源项目之一。)AMPLab是当时学界最先进的大数据实验室,戴金权的团队与AMPLab紧密合作,将业界客户的需求和前沿的研究匹配起来,逐渐将Spark开源平台变成了工业界最先进的大数据标准平台。

在围绕Spark的大数据分析技术,比如实时流式分析、高级的图分析、机器学习等方面,戴金权的团队始终处在业界领先的地位。他们为很多大型互联网公司提供了大数据分析的技术支持。比如2012年,戴金权团队帮助优酷使用Spark做分布式的大数据分析,使得其图分析的效率提高了13倍以上,优酷成为当时分布式Spark大数据技术的最早一批使用者。他们还帮助腾讯在Spark上面构建大规模稀疏机器学习模型,将模型规模的量级提高了十倍以上,模型的训练速度提高了四倍以上。
“业界的需求和前沿的研究共同决定了技术发展的路径,我觉得这两方面都很重要。”戴金权说道,“用户面临着大数据方面的挑战和需求,但是并不会知道有哪些更高效的技术可以解决问题,因此我们发现了用户的需求以后,就需要从研究的角度出发,与学界合作开发出下一代更先进的技术。”
现阶段,Spark已经成为被广泛使用的大数据分析平台框架。另一方面,人工智能技术愈发成熟,学界前沿的研究社区不断推出创新的深度学习算法。
戴金权认为:在大数据平台上进行大规模分布式机器学习和深度学习,会是下一个方向。
但是,戴金权发现,在大数据处理和深度学习模型算法之间有很大的鸿沟。“深度学习顶尖研究人员不断地在模型上有所突破,但是数据科学家、分析师、普通用户却很难将模型应用到现实生产环境的大数据社区当中去。”

先进的深度学习技术如何能够跨域鸿沟,让大多数“沉默的普通用户”使用呢?目前主流的深度学习框架Caffe、Torch、TensorFlow对于普通用户来说并不友好。
“思考如何让大数据用户高效、方便地使用前沿的人工智能技术,是我们当时的出发点。”戴金权说道。
为了弥补这一鸿沟,戴金权带领团队推出了BigDL分布式深度学习框架,可以直接在现有的Hadoop和Spark集群上运行,真正将大数据分析与人工智能结合起来,让更多的大数据用户、数据工程师、数据科学家、数据分析师能够方便地在大数据平台上使用人工智能技术。
戴金权总是能深刻洞察到用户更进一步的需求。在跟客户进行BigDL的合作项目时,他发现,BigDL、Tensorflow这些框架离最终的AI应用还是有很大的鸿沟。因为工业级AI系统涉及到非常复杂大数据分析流水线,深度学习模型只是整个流程的一部分(DT君注:下图中的黑色框部分),除此之外,还有数据导入、数据清洗、特征提取等等工作。
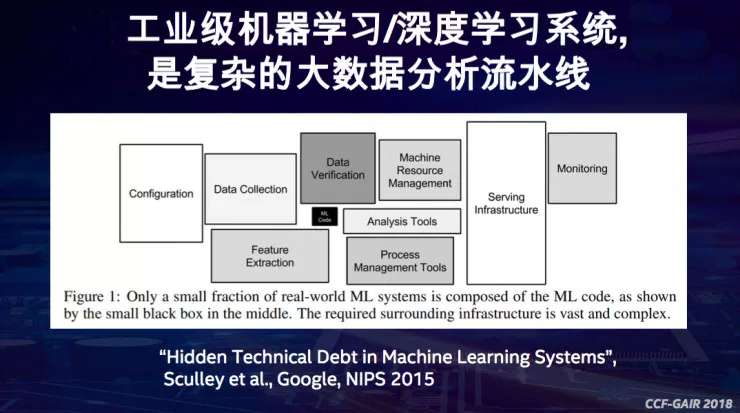
戴金权开始思考如何将数据处理、机器学习以及算法很好地和大数据处理工作流整合在一起。
2017年1月英特尔开源BigDL,半年后,戴金权的团队在Apache Spark、BigDL、TensorFlow等的基础上又构建了Analytics Zoo这一更高级的大数据分析+AI的平台。用户通过非常少的代码就可以使用高级的深度学习模型,很方便地构建大数据分析与深度学习的应用,深度学习技术的使用门槛和成本被大大降低了,哪怕数据分析师不会写任何代码,只会写SQL,仍然能将人工智能用起来。
“BigDL和 Analytics Zoo能将前沿的人工智能技术和大数据平台相结合,并在现实生产环境中应用。”戴金权说道。
在现实的生产环境中,BigDL和 Analytics Zoo能够将深度学习模型高效地整合进大数据分析的整个流水线之中。在与京东的合作案例中,京东的分布式存储系统中有几亿张图片,如何把这几亿张图片从大数据系统中读取出来并高效地处理是一个大难题。京东刚开始使用的GPU方案在开发、部署、性能方面都碰到问题。戴金权团队将应用迁移到Spark和BigDL平台上之后,运维效率与之前的方案相比达到了3到4倍的提升。

BigDL和 Analytics Zoo弥补了大数据社区和前沿深度学习技术之间的鸿沟,也架起了大数据和人工智能之间的桥梁。
目前,BigDL和Analytics Zoo的技术已经在开源社区中被全球大数据用户所使用,并且能在包括AWS、Azure、阿里云、百度云等几乎所有的公有云平台上使用。
“大数据技术和人工智能逐渐成为普惠科技是技术发展的必然趋势。”戴金权解释道,“先进的技术成果一开始是研究性质的东西,慢慢地跟工业级的系统相结合,然后通过开源增加影响力,让用户能够广泛地使用。”

2016年,英特尔开始进行战略转型,计划从PC公司转向一家支持云计算和数以十亿计的智能计算设备的公司。这意味着英特尔从一家老牌芯片公司转型为数据公司,将触角延伸到了截然不同的数据科学领域,涵盖虚拟现实、无人驾驶、工业互联网、云、5G等领域。
现在,英特尔的研究团队正在探索下一代人工智能技术,比如神经拟态计算(类脑计算),他们测试了全球首款具有自我学习能力的芯片 Loihi,可以解决一些当前的深度学习不能解决的问题,例如稀疏编码、词典学习、动态学习适应结果的一些问题。
“Loihi是一个夏威夷火山的名称,意味着这项技术一旦爆发的话,将会改变非常多的计算模式。”虽然这项新技术的应用场景还不是很明晰,但戴金权对它寄予了非常大的期望。
不管下一代技术如何发展,戴金权认为自己一直在做的工作是将前沿的AI研究和技术进行预研,再通过构建工业级的开源平台,让先进的AI技术能够非常好地让广大用户使用。
不远的未来,AI也许能够成为我们日常工作生活中不可或缺的工具,变得像美颜相机一样简单易用,小公司和个人也能利用AI的力量创造出更大的价值。
戴金权,英特尔高级首席工程师、大数据技术全球CTO。负责领导英特尔全球(位于硅谷和上海)的工程团队在高级大数据分析(包括分布式机器学习和深度学习)上的研发工作,他带领团队一手研发了基于Apache Spark 框架的分布式深度学习库 BigDL,并在Apache Spark、BigDL、TensorFlow等的基础上又构建了Analytics Zoo大数据分析和人工智能的平台,致力于将AI技术普世化,让AI技术离大众更近一点。

“数据科学50人”项目是DT财经旗下数据侠计划重点内容产品,与数据科学领域KOL挖掘数据内容的价值。我们从商业数据科学领域选出最具代表性的50位先锋进行深度专访,50人由DT财经独立评审并发布,第一财经数据科技及合作伙伴倾力支持。


数据侠计划是由第一财经旗下DT财经发起的数据社群,包含数据侠专栏、数据侠实验室系列活动和数据侠联盟,旨在聚集大数据领域精英,共同挖掘数据价值。申请入群请添加微信公号dtcaijing003并备注“数据社群”,合作请联系datahero@dtcj.com。

分享这篇文章到
2019-08-30

2019-05-08

2019-03-19

2019-02-28